Here are the list of Sql Server Architecture Questions and Answers which are asked in SQL Server developer / DBA interviews
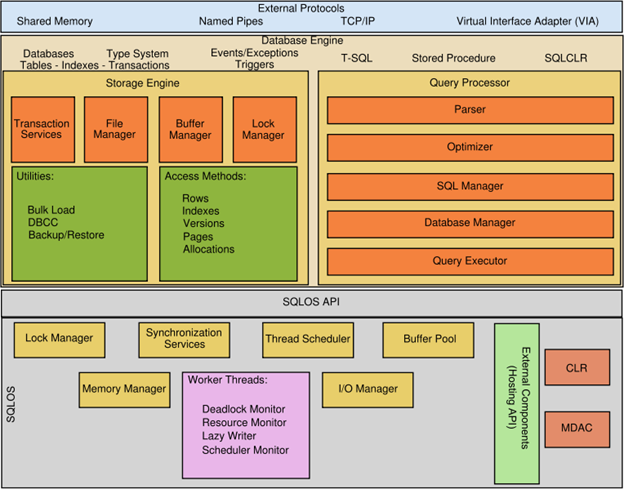
Q. Can you draw SQL Server architectural diagram with all the components?
Ans:
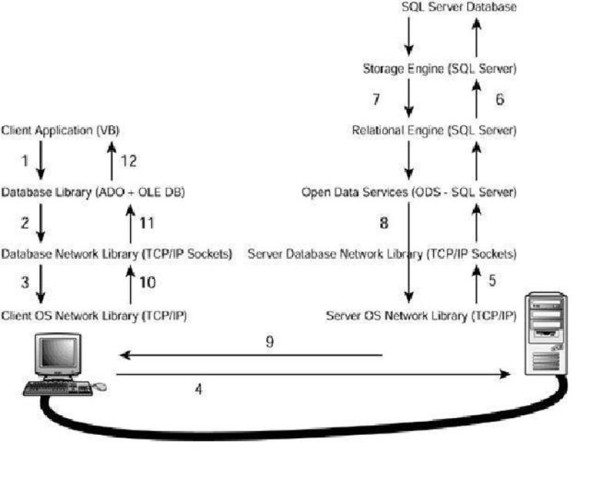
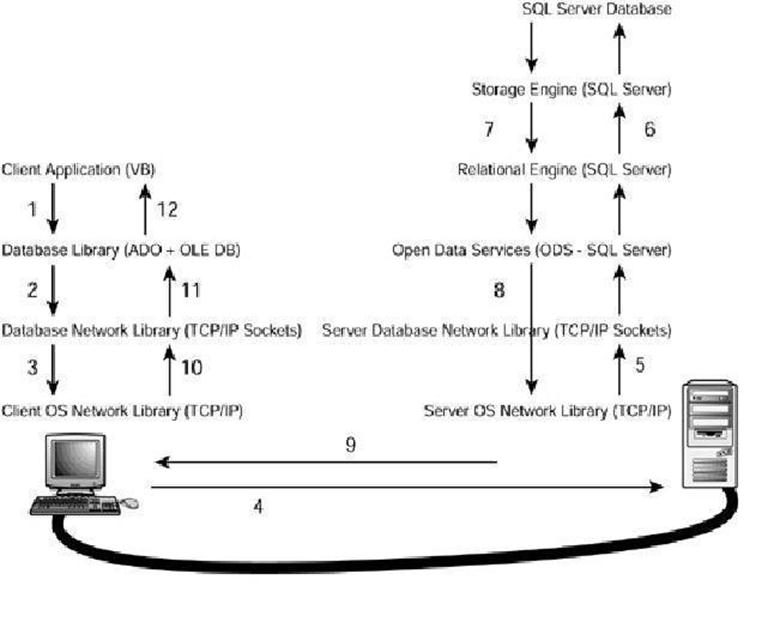
Network Flow – SQL Server Architecture
Q. Can you explain the network flow in SQL Server Architecture?
Ans:
These steps are defined as follows:
1. The user selects an option in a client application. This option calls a function in the client application that generates a query that is sent to SQL Server. The application uses a database access library to send the query in a way SQL Server can understand.
2. The database library transforms the original request into a sequence of one or more Transact-SQL statements to be sent to SQL Server. These statements are encapsulated in one or more Tabular Data Stream (TDS) packets and passed to the database network library to be transferred to the server computer.
3. The database network library uses the network library available in the client computer to repackage the TDS packets as network protocol packets.
4. The network protocol packets are sent to the server computer network library across the network, where they are unwrapped from their network protocol.
5. The extracted TDS packets are sent to Open Data Services (ODS), where the original query is extracted.
6. ODS sends the query to the relational engine, where the query is optimized and executed in collaboration with the storage engine.
7. The relational engine creates a result set with the final data and sends it to ODS.
8. ODS builds one or more TDS packets to be sent to the client application, and sends them to the server database network library.
9. The server database network library repackages the TDS packets as network protocol packets and sends them across the network to the client computer.
10. The client computer receives the network protocol packets and forwards them to the network libraries where the TDS packets are extracted.
11. The network library sends the TDS packets to the database access library, where these packets are reassembled and exposed as a client result set to the client application.
12. The client application displays information contained in the result sets to the user.
Pages and Extents
Q. What is a page in database systems and tell me something about pages?
Ans:
The fundamental unit of data storage in SQL Server is the page.
Page size is 8kb means 128 pages = 1 MB.
Page starts with the header of 96 bytes that is used to store page number, page type, the amount of free space on the page, and the object id that owns the page. The maximum size of a single row on a page is 8060 bytes. But this restriction is relaxed for tables which are having varchar, nvarchar, Varbinary, Taxt or Image columns.
Q. Any idea what is “ROW_OVERFLOW_DATA allocation unit”?
Ans:
When the total row size of all fixed and variable columns in a table exceeds the 8,060 byte limitation, SQL Server dynamically moves one or more variable length columns to pages in the ROW_OVERFLOW_DATA allocation unit.
This is done whenever an insert or update operation increases the total size of the row beyond the 8060 byte limit. When a column is moved to a page in the ROW_OVERFLOW_DATA allocation unit, a 24-byte pointer on the original page in the IN_ROW_DATA allocation unit is maintained. If a subsequent operation reduces the row size, SQL Server dynamically moves the columns back to the original data page.
Q. Can you briefly describe about EXTENT?
Ans:
An extent is eight physically contiguous pages, or one extent = 64 KB. That means 16 Extents= 1 MB.
There are two types of Extents. Uniform Extents and Mixed Extents.
Uniform extents are owned by a single object;
Mixed extents are shared by up to eight objects
Q. What are the different Types of Pages available?
Ans:
GAM and SGAM (Global Allocation Map & Shared GAM):
GAM: Extents have been allocated: 1 – Free space 0 – No space
SGAM: Mixed Extents have been allocated: 1 – Free Space + Mixed Extent and 0 – No space
Each GAM / SGAM covers 64000 extents – 4 GB
PFS (Page Free Space): Percentage of free space available in each page in an extent.
DCM (Differential Changed Map): This tracks the extents that have changed since the last BACKUP DATABASE statement. 1 – Modified, 0 – Not modified
BCM (Bulk Changed Map): This tracks the extents that have been modified by bulk logged operations since the last BACKUP LOG statement. 1 – Modified, 0 – Not modified (Used only in bulk logged Recovery model)
In each data file pages are arranged like below
Along with that we have three different data pages
Data
Index
Text/ Image (LOB, ROW_OVERFLOE, XML)
Files and File Groups
Q. Have you ever heard the word “Files” or “File Groups” in SQL Server?
Ans:
Files: There are three types, Primary- .mdf, Secondary – .ndf and Log files – .ldf
File Groups: There are two, Primary File Group – All system tables and User Defined – Depends
All secondary files and user defined file groups are created to optimize the data access and for partitioning the tables.
Q. What are the advantages and disadvantages over using filegroups?
Ans:
Advantages:
Using filegroups, you can explicitly place database objects into a particular set of database files. For example, you can separate tables and their nonclustered indexes into separate filegroups. This can improve performance, because modifications to the table can be written to both the table and the index at the same time. This can be especially useful if you are not using striping with parity (RAID-5).
Another advantage of filegroups is the ability to back up only a single filegroup at a time. This can be extremely useful for a VLDB, because the sheer size of the database could make backing up an extremely time-consuming process.
Yet another advantage is the ability to mark the filegroup and all data in the files that are part of it as either read-only or read-write.
Disadvantages
The first is the administration that is involved in keeping track of the files in the filegroup and the database objects that are placed in them.
The other is that if you are working with a smaller database and have RAID-5 implemented, you may not be improving performance.
Transaction log Architecture
Q. Can you talk about “Transactionlog” Logical and Physical architecture?
Ans:
“Transactionlog” Logical Architecture:
Each log record is identified by a unique number called LSN (Log Sequence Number). A log record contains the LSN, TransactionID to which it belongs and data modification record.
Data modification record: It’s either operation performed or before and after data image
When recorded “Operation Performed”
Transaction committed – Logical Operation is permanently applied to the data
Transaction rollback – Reverse Logical Operation is applied to the data.
When Recorded “Before and After Data Image”
Transaction committed – Applied the after transaction image
Transaction rollback – Applied the before transaction image
“Transactionlog” Physical Architecture:
The transaction log is used to guarantee the data integrity of the database and for data recovery.
The SQL Server Database Engine divides each physical log file internally into a number of virtual log files. Virtual log files have no fixed size, and there is no fixed number of virtual log files for a physical log file.
The only time virtual log files affect system performance is if the log files are defined by small size and growth_increment values. If these log files grow to a large size because of many small increments, they will have lots of virtual log files. This can slow down database startup and also log backup and restore operations.
Q. What are the CheckPoints in SQL Server database?
Ans:
Checkpoints flush dirty data pages from the buffer cache of the current database to disk. This minimizes the active portion of the log that must be processed during a full recovery of a database. During a full recovery, the following types of actions are performed:
The log records of modifications not flushed to disk before the system stopped are rolled forward.
All modifications associated with incomplete transactions, such as transactions for which there is no COMMIT or ROLLBACK log record, are rolled back.
Before a database backup, the Database Engine automatically performs a checkpoint so that all changes to the database pages are contained in the backup. Also, stopping a server issues a checkpoint in each database on the server.
Q. What is an Active Log?
Ans:
The section of the log file from the MinLSN to the last-written log record is called the active portion of the log, or the active log. This is the section of the log required to do a full recovery of the database. No part of the active log can ever be truncated. All log records must be truncated from the parts of the log before the MinLSN.
Q. What is “Write Ahead Transaction Log”?
Ans:
SQL Server uses a write-ahead log (WAL), which guarantees that no data modifications are written to disk before the associated log record is written to disk.
Data modifications are not made directly to disk, but are made to the copy of the page in the buffer cache. The modification is not written to disk until a checkpoint occurs in the database. A page modified in the cache, but not yet written to disk, is called a dirty page. The internal process that actually goes on:
Copy of the data pages are pulled and placed in buffer cache
Applied the operation on the pages that are on buffer cache
Write the log record details (Pages modified) to Disk
Write / flush /apply the page to the disk
If step 4 happens before the step 3 then rollback is impossible. SQL Server takes the responsibility of writing the log details to disk before flushing the dirty pages.
Memory Management Architecture
Q. Can you describe SQL Server Memory Architecture?
Ans:
SQL Server dynamically acquires and frees memory as required. Typically, an administrator need not have to specify how much memory should be allocated to SQL Server, although the option still exists and is required in some environments.
SQL Server supports Address Windowing Extensions (AWE) allowing use of physical memory over 4 gigabytes (GB) on 32-bit versions of Microsoft Windows operating systems. This feature is deprecated from Dinali 2012.
SQL Server tries to reach a balance between two goals:
Keep the buffer pool from becoming so big that the entire system is low on memory.
Minimize physical I/O to the database files by maximizing the size of the buffer pool.
Q. Do you have any idea about Buffer Management?
Ans:
A buffer is a 8kb size in memory. To reduce the I/O operations from database to disk buffer manager use the buffer cache. BM gets the data from database to buffer cache and modifies the data and the modified page is sent back to the disk
The buffer manager only performs reads and writes to the database. Other file and database operations such as open, close, extend, and shrink are performed by the database manager and file manager components.
Q. Explain effects of Min and Max memory configuration options
Ans:
The min server memory and max server memory configuration options establish upper and lower limits to the amount of memory used by the buffer pool of the Microsoft SQL Server Database Engine. The buffer pool starts with only the memory required to initialize. As the Database Engine workload increases, it keeps acquiring the memory required to support the workload. The buffer pool does not free any of the acquired memory until it reaches the amount specified in min server memory. Once min server memory is reached, the buffer pool then uses the standard algorithm to acquire and free memory as needed. The only difference is that the buffer pool never drops its memory allocation below the level specified in min server memory, and never acquires more memory than the level specified in max server memory.
Thread and Task Architecture
Q. Can you describe how SQL Server handles Batch or Task Scheduling?
Ans:
Each instance must handle potentially thousands of concurrent requests from users. Instances of SQL Server use Microsoft Windows threads, or if configured, they use fibers, to manage these concurrent tasks efficiently. This includes one or more threads for each server Net-Library, a network thread to handle network I/O, and a signal thread for communicating with the Service Control Manager.
Understanding Scheduling: Each instance of SQL Server has an internal layer (SQL OS/Kernel) that implements an environment similar to an operating system. This internal layer is used for scheduling and synchronizing concurrent tasks without having to call the Windows kernel.
Connection: A connection is established when the user is successfully logged in. The user can then submit one or more Transact-SQL statements for execution. A connection is closed when the user explicitly logs out, or the connection is terminated.
Batch: An SQL batch is a set of one or more Transact-SQL statements sent from a client to an instance of SQL Server for execution.
Task: A task represents a unit of work that is scheduled by SQL Server. A batch can map to one or more tasks.
Windows thread: Each Windows thread represents an independent execution mechanism.
Fiber: A fiber is a lightweight thread that requires fewer resources than a Windows thread. One Windows thread can be mapped to many fibers.
Worker thread: The worker thread represents a logical thread (Task) in SQL Server that is internally mapped (1:1) to either a Windows thread or, if lightweight pooling is turned ON, to a fiber. The mapping can be done till the free worker threads available. (Parameter: Max worker Threads)
Thread and Fiber Execution: Microsoft Windows uses a numeric priority system that ranges from 1 through 31 to schedule threads for execution. Zero is reserved for operating system use. When several threads are waiting to execute, Windows dispatches the thread with the highest priority.
By default, each instance of SQL Server is a priority of 7, which is referred to as the normal priority. The priority boost configuration option can be used to increase the priority of the threads from an instance of SQL Server to 13. This is referred to as high priority.
The performance of any instances running at normal priority can be adversely affected. Also, the performance of other applications and components on the server can decline if priority boost is turned on.
Query Processing Architecture
Q. I have submitted a Query to SQL Server from an Application and I got the reply as “data inserted successfully”. Can you demonstrate what the processing done inside?
Ans:
When you submit a query to a SQL Server database, a number of processes on the server go to work on that query. The purpose of all these processes is to manage the system such that it will provide your data back to you, or store it, in as timely a manner as possible, whilst maintaining the integrity of the data.
All these processes go through two stages:
1. Relational Engine
2. Storage Engine
At Client:
1. User enter data and click on submit
2. The client database library transforms the original request into a sequence of one or more Transact-SQL statements to be sent to SQL Server. These statements are encapsulated in one or more Tabular Data Stream (TDS) packets and passed to the database network library
3. The database network library uses the network library available in the client computer to repackage the TDS packets as network protocol packets.
4. The network protocol packets are sent to the server computer network library across the network
At Server:
5. The extracted TDS packets are sent to Open Data Services (ODS), where the original query is extracted.
6. ODS sends the query to the relational engine
7. A connection established to the relational engine and assign a SID to the connection
At Relational Engine:
8. Check permissions and determines if the query can be executed by the user associated with the request
9. Query sends to Query Parser
It checks that the T-SQL is written correctly
Build a Parse Tree \ Sequence Tree
10. Parse Tree sends to Algebrizer
Verifies all the columns, objects and data types
Aggregate Binding (determines the location of aggregates such as GROUP BY, and MAX)
Builds a Query Processor Tree in Binary Format
11. Query Processor Tree sends to Optimizer
Based on the query processor tree and Histogram (Statistics) builds an optimized execution plan
Stores the execution plan into cache and send it to the database engine
At Database Engine:
12. Database engine map a batch into different tasks
13. Each task associated with a process
14. Each process assigned with a Windows Thread or a Windows Fiber. The worker thread takes care of this.
15. The Thread/Fiber send to the execution queue and wait for the CPU time.
16. The Thread/Fiber identifies the table location where the data need to be stored
17. Go to the file header, checks the PFS, GAM and GSAM and go to the correct page
18. Verifies the page is not corrupted using Torn page Detection / Check SUM and writes the data
19. If require allocates new pages and stores data on it. Once the data is stored/updated/added in a page, it updates the below locations
PFS
Page Header – Checksum / Torn Page Detection (Sector info)
BCM
DCM
20. In this process the
Memory manager take care of allocating buffers, new pages etc,
Lock manager take care of allocating appropriate locks on the objects/pages and releasing them when task completed
Thread Scheduler: schedules the threads for CPU time
I/O manager: Establish memory bus for read/write operations from memory to disk and vice versa
Deadlock\Resource\Scheduler Monitor: Monitors the processes
21. If that is a DML operation, it picks the appropriate page from disk and put the page in Memory.
22. While the page is available on Memory based on the ISOLATION LEVEL an shared / exclusive / update / Schema lock issued on that page.
23. Once the page is modified at Memory, that means once the transaction completed the transactional operation logged into log file (.ldf) to the concerned VLF.
24. Here we should understand that only the operation (T-SQL statements) logged into ldf file. The modified page waits in memory till check point happens. These pages are know as dirty pages as the page data is differ in between the page on Disk and Memory.
25. Once the checkpoint happens the page will be written back to the disk.
26. Once the process is completed the result set is submitted to the relational engine and follow the same process for sending back the result set to client application.
27. The connection will be closed and the SID is removed
Network Protocols
Q. What are the different types of network protocols? Explain each of them in detail
Ans:
Shared Memory:
Clients using the shared memory protocol can only connect to a SQL Server instance running on the same computer; it is not useful for most database activity. Use the shared memory protocol for troubleshooting when you suspect the other protocols are configured incorrectly.
Server – Machine 1
Clients – Machine 1
TCP/IP:
TCP/IP is a common protocol widely used over the Internet. It communicates across interconnected networks of computers that have diverse hardware architectures and various operating systems. TCP/IP includes standards for routing network traffic and offers advanced security features. It is the most popular protocol that is used in business today.
Server – Machine 1
Clients – WAN (Any machine from any network)
Named Pipes:
Named Pipes is a protocol developed for local area networks. A part of memory is used by one process to pass information to another process, so that the output of one is the input of the other. The second process can be local (on the same computer as the first) or remote (on a networked computer).
Server – Machine 1
Clients – LAN (Any machine from LAN)
VIA:
Virtual Interface Adapter (VIA) protocol works with VIA hardware. This feature will be deprecated in future releases.
Miscellaneous
Q. What is Instant File Initialization and how it works?
Ans:
On Windows systems when SQL Server needs to write something on disk, first it verify that the hard disk space is trustworthy means the space is readable. The verification process is:
SQL Server writes zeros to the file
This process is known as zeroing process
SQL Server uses single thread for zeroing process
The actual operation that triggers this verification should wait until this verification process completed.
If Instant File Initialization is enabled for SQL Server, it skips the zeroing process for data files and reduces the wait time.
Q. What are the database activities that get benefit from Instant File Initialization?
Ans:
Creating a new Database
Restoring a database from backup file
Increasing database data file size manually
Increasing database data file size due to Auto Growth option
TEMPDB creation at the time of SQL Server restart
Note: Remember growing log file still uses the zeroing process
Q. There is a big change happened in SQL Server Log architecture on SQL Server 2014. Do you have any idea on that?
Ans:
Yes! VLF creation algorithm got changed from SQL Server 2014 which results into a smaller number of VLF when compared to the earlier (Before 2014) algorithms.
Before SQL Server 2014:
Up to 64 MB: 4 new VLFs, each roughly 1/4 the size of the growth
64 MB to 1 GB: 8 new VLFs, each roughly 1/8 the size of the growth
More than 1 GB: 16 new VLFs, each roughly 1/16 the size of the growth
From SQL Server 2014:
Is the growth size less than 1/8 the size of the current log size?
Yes: create 1 new VLF equal to the growth size
No: Use the Formula (8 VLF if Auto Growth > 1/8 of total log file)
Q. How Min and Max server memory options impact memory usage from SQL Server?
Ans:
The min server memory and max server memory configuration options establish upper and lower limits to the amount of memory used by the buffer pool of the Microsoft SQL Server Database Engine. The buffer pool starts with only the memory required to initialize. As the Database Engine workload increases, it keeps acquiring the memory required to support the workload. The buffer pool does not free any of the acquired memory until it reaches the amount specified in min server memory. Once min server memory is reached, the buffer pool then uses the standard algorithm to acquire and free memory as needed. The only difference is that the buffer pool never drops its memory allocation below the level specified in min server memory, and never acquires more memory than the level specified in max server memory.
Q. What are the different types of memory?
Ans:
Physical Memory: The actual memory installed on mother board.
Virtual Memory: Total Physical Memory + Page File
Page File: When available memory can’t serve the coming requests it starts swapping pages to disk to the page file. The current page file size we can get from “sysdm.cpl” à Advanced à Performance Settings –> Advanced
Cached memory: It holds data or program code that has been fetched into memory during the current session but is no longer in use now.
Free memory: It represents RAM that does not contain any data or program code and is free for use immediately.
Working Set: Amount of memory currently in use for a process. Peak Working Set is the highest value recorded for the current instance of this process. Consistently Working Set < Min Server Memory and Max Server Memory means SQL Server is configured to use too much of memory.
Private Working Set: Amount of memory that is dedicated to that process and will not be given up for other programs to use.
Sharable Working Set: Shareable Working Set can be surrendered if physical RAM begins to run scarce
Commit Size: The total amount of virtual memory that a program has touched (committed) in the current session. Limit is Maximum Virtual Memory that means Physical RAM + Page File + Kernel Cache.
Hard faults / Page Faults: Pages fetching from the page file on the hard disk instead of from physical memory. Consistently high number of hard faults per second represents Memory pressure.
Q. I have restarted my windows server. Can you be able to explain how memory allocation happens for SQL Server?
Ans:
Memory allocation is always depends on CPU architecture.
32 Bit:
Initially allocates memory for “Memory To Leave” (MTL) also known as VAS Reservation (384 MB). This MTL value can be modified using the start parameter “–g”
Then Allocates memory for Buffer Pool = User VAS – MTL (Reserved VAS) = Available VAS
Maximum BPool Size = 2048 MB – 384 MB = 1664 MB.
64 Bit:
Allocates Memory for Buffer Pool based on Maximum Server Memory configuration
Non-Buffer Pool Memory region (MTL / VAS Reservation) = Total Physical Memory – (Max Server Memory + Physical Memory Used by OS and Other Apps)
Ex: Windows Server is having 64 GB physical memory; SQL Server Max Server Memory = 54 GB and OS and other apps are using 6 GB than the memory available for
Q. Can you technically explain how memory allocated and lock pages works?
Ans:
Windows OS runs all processes on its own Virtual Memory known as Virtual Address Space and this VAS is divided into Kernel (System) and User (Application) mode.
Default: No Lock Pages in Memory is enabled
SQL Server memory allocations made under User Mode VAS using VirtualAlloc() WPI function.
Any memory that allocates via VirtualAlloc () can be paged to disk.
SQLOS resource monitor checks QueryMemoryResourceNotification windows API and when windows sets Memory Low notification, SQLOS responds to that request by releasing the memory back to windows.
Lock Pages in Memory is Enabled for SQL Server:
SQL Server memory allocations are made using calls to the function AllocateUserPhysicalPages () in AWE API.
Memory that allocates using AllocateUserPhysicalPages () is considered to be locked. That means these pages should be on Physical Memory and need not be released when a Memory Low Notification on Windows.
Q. What is the architecture for In-Memory OLTP? Does it’s a separate component or how SQL Server handles a request when they need both disk based and memory optimized objects?
Ans:
SQL Server 2014 and 2016 are having hybrid architecture by combining the both traditional database and In-Memory OLTP engine. There are 4 components created in In-Memory architecture
In-Memory OLTP Compiler:
This is for compiling “stored procedures” which are created as “Natively Compiled Stored Procedures” and also it compiles the incoming request to extract the natively compiled stored procedure dll entry point.
Natively Compiled SP’s and Schema:
It holds the compiled code for natively compiled stored procedures.
In-Memory OLTP Storage Engine:
It manages user data and indexes of the memory optimized tables. It provides transactional operations on tables of records, hash and range indexes on the tables, and base mechanisms for storage, check pointing, recovery and high-availability. For a durable table, it writes data to FILESTREAM based FILEGROUP on disk so that it can recover in case a server crashes. It also logs its updates to the SQL Server database transaction log along with the log records for disk based tables. It uses SQL Server file streams for storing checkpoint files.
Memory Optimized Table FILEGROUP:
The most important difference between memory-optimized tables and disk-based tables is that pages do not need to be read into cache from disk when the memory-optimized tables are accessed. All the data is stored in memory, all the time. A set of checkpoint files (data and delta file pairs), which are only used for recovery purposes, is created on files residing in memory-optimized FILEGROUP that keep track of the changes to the data, and the checkpoint files are append-only. Operations on memory-optimized tables use the same transaction log that is used for operations on disk-based tables, and as always, the transaction log is stored on disk.
Book for SQL Server Interview Questions and Answers for Experienced and Freshers….1000+ questions covered, check here for sample questions
Sandeep, yes we have wrongly mentioned. Updated the post, thanks a lot for correcting.
bobby
11 years ago
Hi uday,
Is these questions are all related to SQL Server 2008 R2 ?
Thanks.
prakash
11 years ago
hi….udhay ji
i m prakah. i m getting trained on sql server dba in a training center.your posts are helping a lot to my interview preparation. could you please mail me the clustering process as it is a real time concept, i m noting finding in any other sites……if possible.
Thanks&Regards
Prakash
nazeer
10 years ago
Really this answers are very nice and useful.
Kaushal Kishor
10 years ago
Hi Uday
I am Kaushal
could you please mail me the Mirroring ,replication and clustering process as it is a real time concept, i m noting finding in any other sites……if possible.
But Can you please explain that what happen inside in SQL when we execute an Update Query.
No Doubt its a great post. but you should include the working of Buffer Pool, Log Pool, Lazy Writer, Check Point, Log Writer, Hash Bucket, Temp Db also. then anyone can understand the complete functionality at a single glance.
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
Wasim Raja
9 years ago
Sir,can fresher sql dba or sql BI work in industry like experienced guy 2+ years work,if he or she has good knowledge as real time concept.pls tell me about this.
I am not clear about your question. If my understanding is correct you are a fresher with SQL DBA knowledge and looking for a job.
Yes! In some of the companies people are looking for trained freshers on SQL DBA. But in most of the MNC’s freshers are expected to be flexible in working various technologies based on available open positions. If you got an expert skill on a specific technology you can mention and ask for a position on same technology.
Thanks
The Team SQL
udayarumilli.com
Wasim Raja
9 years ago
Or can fresher get a job in sql dba or sql BI
Wasim Raja
9 years ago
Or can fresher get a job in sql dba or sql BI if he or she has good knowledge like 2 yrs experience
Wasim Raja
9 years ago
Sir i have 2 more question,pls answer me first one is i often seen sql dba job with atleast 2 years experience,now i am fresher but having good knowledge on sql dba like 2 yr exp,then companies will hire me even i am fresher,how can i apply for 2 to 4 yr exp job,,,and second ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
Raja
9 years ago
Sir i have 2 more question,pls answer me first one is i often seen sql dba job with atleast 2 years experience,now i am fresher but having good knowledge on sql dba like 2 yr exp,then companies will hire me even i am fresher,how can i apply for 2 to 4 yr exp job,,,and second ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
Shakir
9 years ago
My ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
Hi, We can not expect a job on SQL DBA position, there are chances if you try well. Research on current market and know the technologies where companies are ready to hire trained freshers. For example in current market there are more professionals required on Data Analytics. At this moment a fresher with a data scientist certification can expect a very good career growth. Do a proper research and get certify and try for a job, remember in IT industry one can’t demand for a specific technology, anyways for any technology communication is the first thing to be considered to… Read more »
Wasim Raja
9 years ago
Thanks a lot,your every article is very helpful for an interview even great real time concepts,go on….
Wasim Raja
9 years ago
Can you send me ssis 2008 and ssrs 2008 projects sample to my mail id i.e wasim1989raja@gmail.com
Hi Uday Arumilli, Your blog is good.
I am a beginner to SQL Server . I came to your blog while searching for SQL Server Architecture. As beginner , What is the order of topics that i have to learn for MS SQL Server to become SQL SERVER DBA. Any reference material.
I also want to learn T-SQL . What topics i have to learn for T-SQL as a beginner to advanced level.
Hi Murali, Sorry for the delayed response. Glad to know that you are interested in SQL Server suite. Since you said you are a beginner, I would strongly suggest a basic point for a successful career: Try to acquire an expert level knowledge in one area (SQL Developer, DBA or MSBI) Never lose a chance to learn new / other technology (Oracle , MySQL, PostGre, NoSQL) Coming to your question for anyone to get the in-depth knowledge you can go through books and articles written by top authors (Ex: Brent Ozer, Itzik Ben-Gan, Adam Machanic etc.) Above all to be… Read more »














{kind=link}
I think you have wrongly mentioned “The maximum size of a single row on a page is 8060KB.”, it must be 8060B instead of 8060KB.
Sandeep, yes we have wrongly mentioned. Updated the post, thanks a lot for correcting.
Hi uday,
Is these questions are all related to SQL Server 2008 R2 ?
Thanks.
hi….udhay ji
i m prakah. i m getting trained on sql server dba in a training center.your posts are helping a lot to my interview preparation. could you please mail me the clustering process as it is a real time concept, i m noting finding in any other sites……if possible.
Thanks&Regards
Prakash
Really this answers are very nice and useful.
Hi Uday
I am Kaushal
could you please mail me the Mirroring ,replication and clustering process as it is a real time concept, i m noting finding in any other sites……if possible.
Kaushal,
You can check on you tune there are lot of wonderful videos from which you can learn these concepts.
Great Stuff
Great Stuff Uday.
Thanks Lavanya.
Good stuff
Thanks Suresh.
Hi Uday,
Really a great post.
But Can you please explain that what happen inside in SQL when we execute an Update Query.
No Doubt its a great post. but you should include the working of Buffer Pool, Log Pool, Lazy Writer, Check Point, Log Writer, Hash Bucket, Temp Db also. then anyone can understand the complete functionality at a single glance.
Thanks
Thanks Anuj, thanks for visiting our blog and will surely work on your suggestions and update the post.
Happy Reading
Uday Arumilli
Nice artical, Thanks a lot for providing information.
Thanks Ram.
Happy Reading
UdayArumilli
Hi Uday,
Great stuff !!
Please can you send me Q&A on high avalibility on Sql 2008 & alwayson SQL 2012 .
Appreciate!!
thanks
Hi Amit,
Thanks for visiting our site.
We are working on SQL Server High- Availability interview questions, Soon will come back with these posts.
Happy Reading
Udayarumilli.com
Thank you. Really a great post.
Thanks Ram.
Happy Reading
http://www.udayarumilli.com
[…] SQL Server Architecture […]
[…] SQL Server Architecture […]
[…] SQL Server Architecture […]
very nice information
Thanks Satya.
Happy Reading
http://udayarumilli.com/
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
64 KB means 16 Extents is wrong.
64 KB means 8 Extents.
Hi Pratap thanks for Visiting us.
I did not mean that 64 kb = 16 extents.
Now separated the statement. You can have a look
Sorry Uday,
64 KB means 1 Extent
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
Sir,can fresher sql dba or sql BI work in industry like experienced guy 2+ years work,if he or she has good knowledge as real time concept.pls tell me about this.
Dear Raja,
I am not clear about your question. If my understanding is correct you are a fresher with SQL DBA knowledge and looking for a job.
Yes! In some of the companies people are looking for trained freshers on SQL DBA. But in most of the MNC’s freshers are expected to be flexible in working various technologies based on available open positions. If you got an expert skill on a specific technology you can mention and ask for a position on same technology.
Thanks
The Team SQL
udayarumilli.com
Or can fresher get a job in sql dba or sql BI
Or can fresher get a job in sql dba or sql BI if he or she has good knowledge like 2 yrs experience
Sir i have 2 more question,pls answer me first one is i often seen sql dba job with atleast 2 years experience,now i am fresher but having good knowledge on sql dba like 2 yr exp,then companies will hire me even i am fresher,how can i apply for 2 to 4 yr exp job,,,and second ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
Sir i have 2 more question,pls answer me first one is i often seen sql dba job with atleast 2 years experience,now i am fresher but having good knowledge on sql dba like 2 yr exp,then companies will hire me even i am fresher,how can i apply for 2 to 4 yr exp job,,,and second ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
My ques is i want to work on complete sql platform on (sql development+sql admin+ssis+ssrs),can i get a opportunity to work various technologies because i want to earn more..pls tell me,,
Hi, We can not expect a job on SQL DBA position, there are chances if you try well. Research on current market and know the technologies where companies are ready to hire trained freshers. For example in current market there are more professionals required on Data Analytics. At this moment a fresher with a data scientist certification can expect a very good career growth. Do a proper research and get certify and try for a job, remember in IT industry one can’t demand for a specific technology, anyways for any technology communication is the first thing to be considered to… Read more »
Thanks a lot,your every article is very helpful for an interview even great real time concepts,go on….
Can you send me ssis 2008 and ssrs 2008 projects sample to my mail id i.e wasim1989raja@gmail.com
Uday,i have not got replied my last ques…
[…] Ref: http://udayarumilli.com/sql-server-architecture-qa-3/ […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
[…] Sql Server Architecture Questions and Answers – sql server architecture questions and answers, SQL server architecture […]
thanku 4 posting about sql,i satisfies ur answer . nice
plz emaile
Thank You!
Happy Reading
The Team SQL
http://www.udayarumilli.com
Why are the pictures not active, tried different browser as well, can you please correct that..
Thanks Subha for pointing out. We have corrected the issue.
Thanks
The Team SQL
http://www.udayarumilli.com
hii
Hi Surekha
Happy Reading
The Team SQL
http://www.udayarumilli.com
Hi Uday Arumilli, Your blog is good.
I am a beginner to SQL Server . I came to your blog while searching for SQL Server Architecture. As beginner , What is the order of topics that i have to learn for MS SQL Server to become SQL SERVER DBA. Any reference material.
I also want to learn T-SQL . What topics i have to learn for T-SQL as a beginner to advanced level.
Hi Murali, Sorry for the delayed response. Glad to know that you are interested in SQL Server suite. Since you said you are a beginner, I would strongly suggest a basic point for a successful career: Try to acquire an expert level knowledge in one area (SQL Developer, DBA or MSBI) Never lose a chance to learn new / other technology (Oracle , MySQL, PostGre, NoSQL) Coming to your question for anyone to get the in-depth knowledge you can go through books and articles written by top authors (Ex: Brent Ozer, Itzik Ben-Gan, Adam Machanic etc.) Above all to be… Read more »
[…] SQL Server Architecture […]
https://social.technet.microsoft.com/wiki/contents/articles/37872.sql-server-installation-on-centos-linux.aspx
[…] Download Image More @ udayarumilli.com […]