Q. What are the primary differences between an index reorganization and an index rebuild?
Ans:
Reorganization is an “online” operation by default; a rebuild is an “offline” operation by default
Reorganization only affects the leaf level of an index
Reorganization swaps data pages in-place by using only the pages already allocated to the index; a rebuild uses new pages/allocations
Reorganization is always a fully-logged operation; a rebuild can be a minimally-logged operation
Reorganization can be stopped mid-process and all completed work is retained; a rebuild is transactional and must be completed in entirety to keep changes
Q. During an index reorganization operation, if the index spans multiple files, will pages be allowed to migrate between files
Ans:
No – pages will not migrate between files during an index reorganization.
Q. If you need to REBUILD a non-clustered index that is 10GB in size and have 5GB of free data-file space available with no room to grow the data file(s), how can you accomplish the task?
Ans:
When rebuilding an existing non-clustered index, you typically require free space that is approximately equivalent to 2.2 times the size of the existing index, since during a rebuild operation, the existing index is kept until the rebuilt structure is complete and an additional approximately 20% free space for temporary sorting structures used during the rebuild operation
In this case, you would require at least an additional 10+ GB of free space for the rebuild operation to succeed, since the index itself is 10GB in size.
Using SORT_IN_TEMPDB would not suffice in this case, since only the temporary sort tables are stored in tempdb in this case, and at least 10 GB of free space would still be required in the database data files.
Your possibilities are different for SQL Server2000 vs. SQL Server 2005/2008:
In SQL Server 2000, you only have 1 option in this case. Drop the index and recreate it.
In SQL Server 2005/2008, you can do the same as you did with SQL Server 2000 (drop, recreate), but you also have another option. If you first disable the index (via the ALTER INDEX…DISABLE statement) the existing space consumed by the index will be freed. Then running a simple ALTER INDEX…REBUILD command will allow the build operation to use the now 15gb of free space to build the index.
Q. What is the Covering Index?
Ans:
If you know that your application will be performing the same query over and over on the same table, consider creating a covering index on the table. A covering index, which is a form of a composite non clustered index, includes all of the columns referenced in SELECT, JOIN, and WHERE clauses of a query. Because of this, the index contains the data you are looking for and SQL Server doesn’t have to look up the actual data in the table, reducing logical and/or physical I/O, and boosting performance.
On the other hand, if the covering index gets too big (has too many columns), this could actually increase I/O and degrade performance.
Q. What is Online Indexing?
Ans:
Online Indexing is a new feature available in SQL Server 2005. In SQL Server 2005, DBAs can create, rebuild, or drop indexes online. The index operations on the underlying table can be performed concurrently with update or query operations. This was not possible in previous versions of SQL Server. In the past, indexing operations (reorganizing or rebuilding) were usually performed as a part of other maintenance tasks running during off-peak hours. During these offline operations, the indexing operations hold exclusive locks on the underlying table and associated indexes. During online index operations, SQL Server 2005 eliminates the need of exclusive locks
The Online indexing feature is very helpful for environments that run 24 hours a day, seven days a week. The Online Indexing feature is available only in the Enterprise Edition of SQL Server 2005/2008.
Q. How Online Indexing works?
Ans:
The online index operation can be divided into three phases:
Preparation
Build
Final
The Build phase is a longest phase of all. It is in this phase where the creation, dropping, or rebuilding of indexes take place. The duration of the Build phase depends on the size of the data and the speed of the hardware. Exclusive locks are not held in this phase, so concurrent DML operations can be performed during this phase. The Preparation and Final phases are for shorter durations. They are independent of the size factor of the data. During these two short phases, the table or the indexed data is not available for concurrent DML operations.
Q. How to know unused indexes in a table.
Ans:
By using a DMV we‘ll find the unused indexes details. We have a DMV called “sys.dm_db_index_usage_stats” which retrieves the statistics of indexes , if an index id is not in that dmv then we can say that index is not been using from a long time.
Q. What are the index limitations?
Ans:
INDEXTYPE – 32 BIT / 64 BIT
NON CLUSTERED – 999 / 999
XML indexes 249 / 249
Columns per index key – 16 / 16 – Only 900 Byte
Q. What are the different indexes available?
Ans:
Index Types
Clustered Index: A clustered index sorts and stores the data rows of the table or view in order based on the clustered index key. The clustered index is implemented as a B-tree index structure that supports fast retrieval of the rows, based on their clustered index key values.
Non Clustered Index: A nonclustered index can be defined on a table or view with a clustered index or on a heap. Each index row in the nonclustered index contains the nonclustered key value and a row locator. This locator points to the data row in the clustered index or heap having the key value. The rows in the index are stored in the order of the index key values, but the data rows are not guaranteed to be in any particular order unless a clustered index is created on the table.
Unique Index: An index that ensures the uniqueness of each value in the indexed column. If the index is a composite, the uniqueness is enforced across the columns as a whole, not on the individual columns. For example, if you were to create an index on the FirstName and LastName columns in a table, the names together must be unique, but the individual names can be duplicated. A unique index is automatically created when you define a primary key or unique constraint:
Primary key: When you define a primary key constraint on one or more columns, SQL Server automatically creates a unique, clustered index if a clustered index does not already exist on the table or view. However, you can override the default behavior and define a unique, nonclustered index on the primary key.
Unique: When you define a unique constraint, SQL Server automatically creates a unique, nonclustered index. You can specify that a unique clustered index be created if a clustered index does not already exist on the table.
Index with Included Columns: A nonclustered index that is extended to include nonkey columns in addition to the key columns. They can be data types not allowed as index key columns. They are not considered by the Database Engine when calculating the number of index key columns or index key size. Need to use INCLUDE clause while creating index.
Full Text Indexes: A special type of token-based functional index that is built and maintained by the Microsoft Full-Text Engine for SQL Server. It provides efficient support for sophisticated word searches in character string data.
Spatial Indexes: A spatial index provides the ability to perform certain operations more efficiently on spatial objects (spatial data) in a column of the geometry data type. The spatial index reduces the number of objects on which relatively costly spatial operations need to be applied.
Filtered Index: An optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes. Use where clause in create index statement.
Composite index: An index that contains more than one column. In both SQL Server 2005 and 2008, you can include up to 16 columns in an index, as long as the index doesn’t exceed the 900-byte limit. Both clustered and nonclustered indexes can be composite indexes.
XML Indexes: A shredded, and persisted, representation of the XML binary large objects (BLOBs) in the xml data type column.
Q. I have a situation where I need to create an index on 20 columns. Is it practically possible? If yes justify?
Ans:
Yes ! We can create an index on 20 columns using INCLUDE clause.
You can include nonkey columns in a nonclustered index to avoid the current index size limitations of a maximum of 16 key columns and a maximum index key size of 900 bytes. The SQL Server Database Engine does not consider nonkey columns when calculating the number of index key columns or the total size of the index key columns. In a nonclustered index with included columns, the total size of the index key columns is restricted to 900 bytes. The total size of all nonkey columns is limited only by the size of the columns specified in the INCLUDE clause; for example, varchar(max) columns are limited to 2 GB. The columns in the INCLUDE clause can be of all data types, except text, ntext, and image.
Q. On which basis we will create computed indexes?
Ans:
For composite indexes, take into consideration the order of the columns in the index definition. Columns that will be used in comparison expressions in the WHERE clause (such as WHERE FirstName = ‘Charlie’) should be listed first. Subsequent columns should be listed based on the uniqueness of their values, with the most unique listed first.
Q. How to design indexes for a database? Or
What are the index creation best practices?
Ans:
Understand the characteristics of the database (OLTP / OLAP)
Understand the characteristics of the most frequently used queries.
Understand the characteristics of the columns used in the queries.
Choose the right index at the right place. For example, creating a clustered index on an existing large table would benefit from the ONLINE index option.
Determine the optimal storage location for the index. A nonclustered index can be stored in the same filegroup as the underlying table, or on a different filegroup. If those filegroups are in different physical drives it will improve the performance.
Database Considerations:
Avoid over indexing
Use many indexes to improve query performance on tables with low update requirements, but large volumes of data.
Indexing small tables may not be optimal
Indexes on views can provide significant performance gains when the view contains aggregations and/or table joins. The view does not have to be explicitly referenced in the query for the query optimizer to use it
Column considerations:
Keep the length of the index key short for clustered indexes. Additionally, clustered indexes benefit from being created on unique or nonnull columns.
Columns that are of the ntext, text, image, varchar(max), nvarchar(max), and varbinary(max) data types cannot be specified as index key columns. However, varchar(max), nvarchar(max), varbinary(max), and xml data types can participate in a nonclustered index as nonkey index columns
Columns that are of the ntext, text, image, varchar(max), nvarchar(max), and varbinary(max) data types cannot be specified as index key columns. However, varchar(max), nvarchar(max), varbinary(max), and xml data types can participate in a nonclustered index as nonkey index columns
Consider using filtered indexes on columns that have well-defined subsets
Consider the order of the columns if the index will contain multiple columns. The column that is used in the WHERE clause in an equal to (=), greater than (>), less than (<), or BETWEEN search condition, or participates in a join, should be placed first.
Index Characteristics: Determine the right index depends on the business need
Clustered versus nonclustered
Unique versus nonunique
Single column versus multicolumn
Ascending or descending order on the columns in the index
Full-table versus filtered for nonclustered indexes
Determine the Fill Factor
Q. Can we create index on table variables?
Yes, Implicitly
Create Index on Table Variable
Creating an index on a table variable can be done implicitly within the declaration of the table variable by defining a primary key and creating unique constraints. The primary key will represent a clustered index, while the unique constraint a non clustered index.
DECLARE @Users TABLE
(
UserID INT PRIMARY KEY,
UserName varchar(50),
UNIQUE (UserName)
)
The drawback is that the indexes (or constraints) need to be unique. One potential way to circumvent this however, is to create a composite unique constraint:
DECLARE @Users TABLE
(
UserID INT PRIMARY KEY,
UserName varchar(50),
FirstName varchar(50),
UNIQUE (UserName,UserID)
)
You can also create the equivalent of a clustered index. To do so, just add the clustered reserved word.
DECLARE @Users TABLE
(
UserID INT PRIMARY KEY,
UserName varchar(50),
FirstName varchar(50),
UNIQUE CLUSTERED (UserName,UserID)
)
Q. What is the Heap Table?
Ans:
HEAP
Data is not stored in any particular order
Specific data cannot be retrieved quickly, unless there are also non-clustered indexes
Data pages are not linked, so sequential access needs to refer back to the index allocation map (IAM) pages
Since there is no clustered index, additional time is not needed to maintain the index
Since there is no clustered index, there is not the need for additional space to store the clustered index tree
These tables have a index_id value of 0 in the sys.indexes catalog view
Q. How to get the index usage information?
Q. Query to retrieve the indexes that are being used?
Ans:
sys.dm_db_index_usage_stats – bind with sysobjects
This view gives you information about overall access methods to your indexes. There are several columns that are returned from this DMV, but here are some helpful columns about index usage:
user_seeks – number of index seeks
user_scans- number of index scans
user_lookups – number of index lookups
user_updates – number of insert, update or delete operations
sys.dm_db_index_operational_stats – bind with sysindexes
This view gives you information about insert, update and delete operations that occur on a particular index. In addition, this view also offers data about locking, latching and access methods. There are several columns that are returned from this view, but these are some of the more interesting columns:
leaf_insert_count – total count of leaf level inserts
leaf_delete_count – total count of leaf level inserts
leaf_update_count – total count of leaf level updates
SELECT DB_NAME(DATABASE_ID) AS DATABASENAME,
OBJECT_NAME(B.OBJECT_ID) AS TABLENAME,
INDEX_NAME = (SELECT NAME
FROM SYS.INDEXES A
WHERE A.OBJECT_ID = B.OBJECT_ID
AND A.INDEX_ID = B.INDEX_ID),
USER_SEEKS,
USER_SCANS,
USER_LOOKUPS,
USER_UPDATES
FROM SYS.DM_DB_INDEX_USAGE_STATS B
INNER JOIN SYS.OBJECTS C
ON B.OBJECT_ID = C.OBJECT_ID
WHERE DATABASE_ID = DB_ID(DB_NAME())
AND C.TYPE <> ‘S’
Q. What is fill factor? How to choose the fill factor while creating an index?
Ans:
The Fill Factor specifies the % of fullness of the leaf level pages of an index. When an index is created or rebuilt the leaf level pages are written to the level where the pages are filled up to the fill factor value and the remainder of the page is left blank for future usage. This is the case when a value other than 0 or 100 is specified. For example, if a fill factor value of 70 is chosen, the index pages are all written with the pages being 70 % full, leaving 30 % of space for future usage.
Q. When to choose High or Low Fillfactor Value?
Ans:
You might choose a high fill factor value when there is very little or no change in the underlying table’s data, such as a decision support system where data modification is not frequent, but on a regular and scheduled basis. Such a fill factor value would be better, since it creates an index smaller in size and hence queries can retrieve the required data with less disk I/O operations since it has to read less pages.
On the other hand if you have an index that is constantly changing you would want to have a lower value to keep some free space available for new index entries. Otherwise SQL Server would have to constantly do page splits to fit the new values into the index pages.
Q. What methods are available for removing fragmentation of any kind on an index in SQL Server?
Ans:
SQL Server 2000:
DBCC INDEXDEFRAG
DBCC DBREINDEX
CREATE INDEX…DROP EXISTING (cluster)
DROP INDEX; CREATE INDEX
SQL Server 2005 and above: The same processes as SQL Server 2000, only different syntax
ALTER INDEX…REORGANIZE
ALTER INDEX…REBUILD
CREATE INDEX…DROP EXISTING (cluster)
DROP INDEX; CREATE INDEX
Q. What page verification options are available in SQL Server and how do they work?
Ans:
SQL Server 2000: Only “Torn Page Detection” is available in SQL Server 2000.
SQL Server 2005: Both “Torn Page Detection” and “Checksum” page verification options exist in SQL Server 2005. Page verification checks help to discover damaged database pages caused by disk I/O path errors. Disk I/O path errors can be the cause of database corruption problems and are generally caused by power failures or disk hardware failures that occur at the time the page is being written to disk.
TORN PAGE DETECTION:
Works by saving a specific bit for each 512-byte sector in the 8-kilobyte (KB) database page and is stored in the database page header when the page is written to disk. When the page is read from disk, the torn bits stored in the page header are compared to the actual page sector information. Unmatched values indicate that only part of the page was written to disk. In this situation, error message 824 (indicating a torn page error) is reported to both the SQL Server error log and the Windows event log. Torn pages are typically detected by database recovery if it is truly an incomplete write of a page. However, other I/O path failures can cause a torn page at any time.
CHECKSUM:
Works by calculating a checksum over the contents of the whole page and stores the value in the page header when a page is written to disk. When the page is read from disk, the checksum is recomputed and compared to the checksum value stored in the page header. If the values do not match, error message 824 (indicating a checksum failure) is reported to both the SQL Server error log and the Windows event log. A checksum failure indicates an I/O path problem. To determine the root cause requires investigation of the hardware, firmware drivers, BIOS, filter drivers (such as virus software), and other I/O path components.
Q. What are the primary differences between an index reorganization and an index rebuild?
Ans:
Reorganization is an “online” operation by default; a rebuild is an “offline” operation by default
Reorganization only affects the leaf level of an index
Reorganization swaps data pages in-place by using only the pages already allocated to the index; a rebuild uses new pages/allocations
Reorganization is always a fully-logged operation; a rebuild can be a minimally-logged operation
Reorganization can be stopped mid-process and all completed work is retained; a rebuild is transactional and must be completed in entirety to keep changes
Q. During an index reorganization operation, if the index spans multiple files, will pages be allowed to migrate between files
Ans:
No – pages will not migrate between files during an index reorganization.
Q. How to make forcefully use an index in a query? Or What table hint needs to be specified to forcefully use an index in a query?
Ans:
We can specify “Index” table hint in a query to forcefully use an index.
Ex: SELECT Emp_ID, Name FROM Emp WITH(INDEX(NIX_NAME_EMP))
Q. What are the index statistics?
Ans:
Index statistics contain information about the distribution of index key values. By distribution, I mean the number of rows associated with each key value. SQL Server uses this information to determine what kind of execution plan to use when processing a query.
Q. When are index statistics updated?
Ans:
The AUTO_UPDATE_STATISTICS database setting controls when statistics are automatically updated. Once statistics have been created, SQL Server then determines when to update those statistics based on how out-of-date the statistics might be. SQL Server identifies out of date statistics based on the number of inserts, updates, and deletes that have occurred since the last time statistics were updated, and then recreates the statistics based on a threshold. The threshold is relative to the number of records in the table. (Enable the properties – “auto create statistics” and “auto update statistics” for OLTP)
Auto Update Statistics: If there is an incoming query but statistics are stale then sql server first update the statistics before building the execution plan.
Auto Update Statistics Asynchronous: If there is an incoming query but statistics are stale then sql servers uses the stale statistics, builds the execution plan and then update the statistics.
Q. How to update statistics manually?
Ans:
If you want to manually update statistics, you can use either sp_updatestats or UPDATE STATISTICS <statistics name>
Q. What are the various types of statistics available?
Ans:
There are three different types of statistics available.
Statistics created due to index creation.
Statistics created by optimizer.
User defined statistics created from “CREATE STATISTICS”
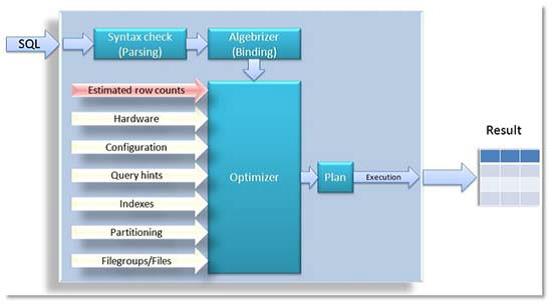
Q. What are the various options to be considered while designing a new execution plan?
Ans:
There are a number of factors that influence the decision in choosing the proper execution plan. One of the most important ones are cardinality estimations, the process of calculating the number of qualifying rows that are likely after filtering operations are applied. A query execution plan selected with inaccurate cardinality estimates can perform several orders of magnitude slower than one selected with accurate estimates. These cardinality estimations also influence plan design options, such as join-order and parallelism. Even memory allocation, the amount of memory that a query requests, is guided by cardinality estimations.
Other factors that influence the optimizer in choosing the execution plan are:
Q. How histogram built?
Ans:
As we all know that when we index a column, SQL Server does two things:
Sorts the values of the column in an internal data structure called “Index” This data structure contains the sorted value and a pointer to its respective row in the table.
Generates a histogram of values.
The histogram shows the distribution of values for the sorted column. For example:
if we have following values in an integer column 1,2,2,3,4,1,4,5,4 then a typical histogram will be similar to this
Value
Rows matched
1
2
2
2
3
1
4
3
5
1
So suppose if you are searching for all rows having column values between 3 and 5 then by looking at the above histogram table you can estimate that you will get total 1+3+1=5 rows. If your table contains just 9 rows in total then 5 rows means approximately 55% of total rows will match the criteria. Based on this calculation you may elect to directly scan the table instead of first reading the index, fetching the pointers of the matching rows and then read the actual rows. Although, it is a very simple example and there are other factors involve in deciding whether to use index or not but this example demonstrates the concept in very simple terms.
Q. How to find out when statistics updated last time?
Ans:
A simple logic is, run the query and observe the values for both “estimated rows” and “actual rows”, if they both are close to each other you need not worried about the statistics. If you find big difference between them then you need to think about updating statistics.
In general we can find out last statistics updated info from below query
select object_name(object_id) as table_name
,name as stats_name
,stats_date(object_id, stats_id) as last_update
from sys.stats
where objectproperty(object_id, ‘IsUserTable’) = 1
order by last_update
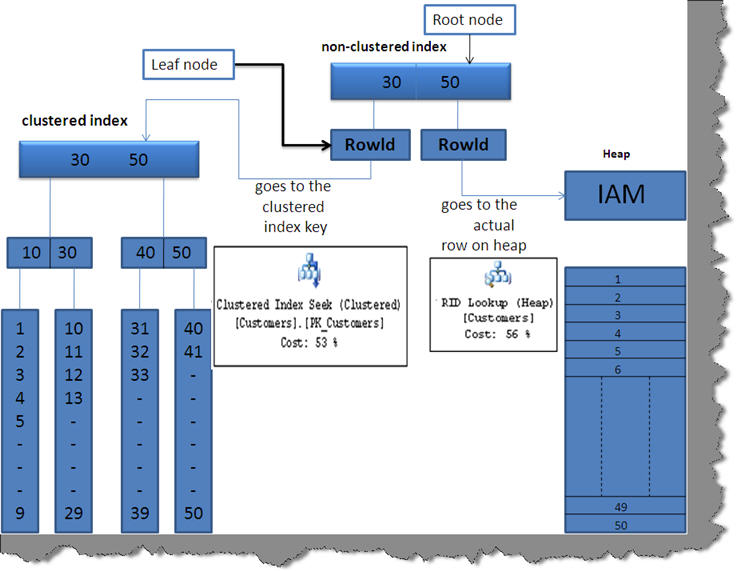
Q. What is RID Lookup \ Bookmark Lookup?
Ans:
RID lookup will be seen when you use non-clustered indexes with join queries.
In order to understand the RID look up we need to first understand how non-clustered indexes work with clustered indexes and heap tables. Below is a simple figure which describes the working and their relationships.
Non-clustered indexes also use the B-tree structure fundamental to search data. In non-clustered indexes the leaf node is a ‘Rowid’ which points to different things depending on two scenarios:-
Scenario 1:- If the table which is having the primary key in the join has a clustered index on the join key then the leaf nodes i.e. ‘rowid’ will point to the index key of clustered index hence a clustered index seek happens
Scenario 2 :- if the table which is having the primary does not have a clustered index then the non-clustered index leaf node ‘rowid’ will point to actual row on the heap table. As the data is stored in a different heap table, it uses the lookup (i.e. RID lookup) to get to the actual row hence an Index seek (Non clustered) with RID lookup happens
I got to know many unknown cocepts of INDEX…Thanks for the wonderful post..Am yet to go through PART1 and PART 3,it tempts me to go through those..Thanks again Uday
Hi Uday!
Can I have a list of useful privileges to be granted for the user/developer to access the SQL Servers/Databases.
For example role that should be granted for a developer to run a job,role that should be granted to a developer to modify a table etc.
ThanksMuch
Saradhi
Dipak
10 years ago
This is very informative stuff.
Do you have any post on blog regarding index scan and index seek?
Please i want urgent based on cluster and always on interview tips with real time issues you have any questions please send me my mail ganjinarendernetha@gmail.com please its very urgent
Hi Narendra, We’ll work on this and share you the details. Remember Clustering is not a big deal it’s a designed feature we just need to enable all required settings and utilize the feature. For clustering you will face questions on: What are the basic requirements for cluster configuration? Can we configure logshipping / Mirroring on a clustered node? How to apply a service patch on a clustering nodes? Basic difference between Active – Active & Active – Passive clusters? A transaction has been started on Node -A , due to a network issue fail over happens to Node-B. What… Read more »
COuld you please explain execution plan with one example which contains all possible combinations and how to implement the suggestions given by execution plan.
Hi Lokendranath, We have been preparing a wast list of interview questions and answers on performance tuning. We’ll surely comeback with the best reference guide. Before that explaining a execution plan with all possible options is very time taking and we need to spend some time but yes we’ll surely include that in our post. I would suggest you to learn below things thereof you can understand the execution plan in-detail: Logical Reads / Physical Reads: It plays vital role in tuning a query Lookup RID / KEY / Bookmark: You would know why covering index for most frequent queries… Read more »
Hi There, You make learning and reading addictive. All eyes fixed on you. Thank you being such a good and trust worthy guide. I am attempting to connect to a server with SSMS 2017 using the [Active Directory – Password] authentication method. When I do, I get this: TITLE: Connect to Server —————————— Cannot connect to XXXX. —————————— ADDITIONAL INFORMATION: A connection was successfully established with the server , but then an error occurred during the login process. (provider: SSL Provider, error: 0 – The certificate chain was issued by an authority that is not trusted.) (Microsoft SQL Server, Error:… Read more »
K Prasad
5 years ago
Hi Uday,
I got to know many unknown concepts of INDEX, Thanks for the wonderful post and i want to know one thing, suppose if we are doing index rebuild/reorganize online/offline what will happen internally, i will wait for you’re reply, thanks for Advanced.
Prasad, Thanks for reaching. Online indexing means performing index maintenance operations (reorganizing or rebuilding) in background while the data still available for access. Before SQL Server 2005 indexing operations were usually performed as a part of other maintenance tasks running during off-peak hours. During these offline operations, the indexing operations hold exclusive locks on the underlying table and associated indexes. During online index operations, SQL Server eliminates the need of exclusive locks Offline indexing is pretty stright forward as it hold an EX lock on complete index. Challenge come-in when you are handling the online indexing in enterprise edition. The… Read more »















I got to know many unknown cocepts of INDEX…Thanks for the wonderful post..Am yet to go through PART1 and PART 3,it tempts me to go through those..Thanks again Uday
Thank You So much Lakshni.
Thanks for visiting our blog.
Happy Reading
Uday Arumilli
Hi Uday!
Can I have a list of useful privileges to be granted for the user/developer to access the SQL Servers/Databases.
For example role that should be granted for a developer to run a job,role that should be granted to a developer to modify a table etc.
ThanksMuch
Saradhi
This is very informative stuff.
Do you have any post on blog regarding index scan and index seek?
Thanks Dipak,
You can get detailed information @ Below links:
Difference between Index Scan and Index Seek:
http://saurabhsinhainblogs.blogspot.in/2014/01/difference-between-index-seek-vs-index.html
http://blogs.msdn.com/b/craigfr/archive/2006/06/26/647852.aspx
Thank you Uday.
You are one of the best mentor for SQL Server.
Dear Bhanu, Thank you So much for visiting our site……you can also contribute through your interviews experience.
Happy Reading
http://www.udayarumilli.com
really use full info uday and bhanu. really good thank you please going on….
Thanks Man.
Happy Reading
http://www.udayarumilli.com
Sql interview questions @ https://intellipaat.com/interview-question/sql-developer-interview-questions/
Hi expert of Sqldba ,
Please i want urgent based on cluster and always on interview tips with real time issues you have any questions please send me my mail ganjinarendernetha@gmail.com please its very urgent
Thanks,
G.Narender
Hi Narendra, We’ll work on this and share you the details. Remember Clustering is not a big deal it’s a designed feature we just need to enable all required settings and utilize the feature. For clustering you will face questions on: What are the basic requirements for cluster configuration? Can we configure logshipping / Mirroring on a clustered node? How to apply a service patch on a clustering nodes? Basic difference between Active – Active & Active – Passive clusters? A transaction has been started on Node -A , due to a network issue fail over happens to Node-B. What… Read more »
[…] Source : sql server performance tuning interview questions indexes […]
[…] (http://udayarumilli.com/sql-server-performance-tuning-interview-questions-part-2-indexes/) […]
Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing.
Thanks for visiting.
Happy Reading
The Team SQL
http://www.udayarumilli.com
Uday you provided us excellent info. really very useful.
thanks a lot.
Thanks for your kind words Sricharan.
Happy Reading
The Team SQL
http://udayarumilli.com/
Hi Uday last one for RID lookup is ultimate.
Thanks for that.
COuld you please explain plan with one example which contains all possible combinations.
Thanks Lokendra for visiting our blog.
Regards
The Team SQL
http://www.udayarumilli.com
COuld you please explain execution plan with one example which contains all possible combinations and how to implement the suggestions given by execution plan.
Hi Lokendranath, We have been preparing a wast list of interview questions and answers on performance tuning. We’ll surely comeback with the best reference guide. Before that explaining a execution plan with all possible options is very time taking and we need to spend some time but yes we’ll surely include that in our post. I would suggest you to learn below things thereof you can understand the execution plan in-detail: Logical Reads / Physical Reads: It plays vital role in tuning a query Lookup RID / KEY / Bookmark: You would know why covering index for most frequent queries… Read more »
[…] Sql Server Indexes […]
Very very useful and nice article uday
Thanks a lot
Thanks Mouli!!!
Happy Learning
SQL THE ONE Team
http://www.udayarumilli.com
It’s nice article and really help to me.
Anyone want more number of
SQL server interview Question and Answer click here.
Once again thank you very much.
Hi There, You make learning and reading addictive. All eyes fixed on you. Thank you being such a good and trust worthy guide. I am attempting to connect to a server with SSMS 2017 using the [Active Directory – Password] authentication method. When I do, I get this: TITLE: Connect to Server —————————— Cannot connect to XXXX. —————————— ADDITIONAL INFORMATION: A connection was successfully established with the server , but then an error occurred during the login process. (provider: SSL Provider, error: 0 – The certificate chain was issued by an authority that is not trusted.) (Microsoft SQL Server, Error:… Read more »
Hi Uday,
I got to know many unknown concepts of INDEX, Thanks for the wonderful post and i want to know one thing, suppose if we are doing index rebuild/reorganize online/offline what will happen internally, i will wait for you’re reply, thanks for Advanced.
Prasad, Thanks for reaching. Online indexing means performing index maintenance operations (reorganizing or rebuilding) in background while the data still available for access. Before SQL Server 2005 indexing operations were usually performed as a part of other maintenance tasks running during off-peak hours. During these offline operations, the indexing operations hold exclusive locks on the underlying table and associated indexes. During online index operations, SQL Server eliminates the need of exclusive locks Offline indexing is pretty stright forward as it hold an EX lock on complete index. Challenge come-in when you are handling the online indexing in enterprise edition. The… Read more »