SQL DBA – INTERVIEW QUESTIONS ANSWERS – 2



SQL Server Database Administrator – Interview Questions
This post “SQL DBA – INTERVIEW QUESTIONS ANSWERS – 2” helps SQL DBA for interview preparation.
Q. Does TRUNCATE is a DDL or DML and why?
Ans:
TRUNCATE is a DDL command as it directly works with table schema instead of row level. This we can observe by using “sys.dm_tran_locks” while executing the “TRUNCATE” command on a table. It issues a schema lock (sch-M) where as “DELETE” issues exclusive lock. Schema lock issued as it requires resetting the identity value.
Q. What is SQL DUMP? Have you ever dealt with this?
Ans:
When SQL Server is crashed or in hung state due to a Memory/Disk/CPU problems it creates a SQL DUMP file. A DUMP files is a file containing a snapshot of the running process (in this case SQL Server) that includes all of the memory space of that process and the call stack of every thread the process has created. There are two major types of DUMP files:
Full DUMP: It contains entire process space and takes lot of time and space
Mini DUMP: It’s a smaller file contains the memory for the call stack of all threads, the CPU registers and information about which modules are loaded.
Q. We are not able to connect to SQL Server. Can you list out what are all the possible issues and resolutions?
Ans:
This is one of the most common problems every DBA should be able to handle with. Here are the list of possible problems and resolutions. All the problems can be categorized into:
- Service Down/Issue
- Network Access/Firewall Issue
- Authentication and Login issue
- SQL Server configuration Issue
- Application Driver or Connection String Issue
Possible Problems:
- Using a wrong instance name/IP or port
- Using a wrong user name or password
- User access might be revoked
- Trying to access from outside organization VPN
- SQL Server is down
- SQL Server is not responding due to high CPU/Memory/Disk I/O
- Might be a disk full issue
- Master database might be corrupted
- User default database may not be online
- SQL Server port might be blocked
- We are using named instance name and SQL Browser service is down
- Using the wrong network protocol
- Remote connections may not be enabled
- Network issue with the host windows server
- Using a wrong client driver (32 bit – 64 bit issues or Old driver using for new version)
- Version Specific issues, for example an application cannot connect to a contained database when connection pooling is enabled. This issue got fixed in SQL Server 2014 CU1
Resolutions:
The error message itself can tell you how to proceed ahead with the resolution:
- If possible first thing should be done is, check SQL Server and Windows error log as it can tell us the exact problem and based on that we can determine the possible best resolution.
- Please cross check connection string information before complaining
- Cross check hosted windows server and SQL Server are up and running
- Make sure the SQL login default database is online and accessible
- Make sure the user access is not revoked
- Make sure all system databases are up and running
- Cross check all resource usage that includes Memory, CPU, Disk I/O, Disk Space etc.
- Try to use IP address and port number instead of instance name, also try with FQDN
- Try to connect from different possible places/systems to make sure the source system has no issues
- Check windows server is reachable from remote location using PING
- Check SQL Server listening on the given port using TELNET <IP> <Port>. Try both from local and remote
- If the port is blocked add this port to exception list in windows firewall INBOUND rules
- Make sure SQL Server is configured to allow remote connections
- If you are also not able to connect then try to connect using DAC and fix the issue by running DBCC commands
- Try if you can connect using SQLCMD
- Cross check if there is any recent changes happened in Active Directory security policy
- Make sure you are using the correct driver to connect to application
- Cross check if there is any blocking on system process
Q. Can you explain how database snapshots works?
Ans:
Let me explain what happens when we create a database snapshot
- It creates an empty file known as sparse file for each source database data file
- Uncommitted transactions are rolled back, thus having a consistent copy of the database
- All dirty pages will be returned to the disk
- The user can query the database snapshot
- Initially the sparse file contains an empty copy of source database data file
- Snapshot data points to the pages from source database datafile
- When any modification occurred (INSERT/DELETE/UPDATE) on source database, all modified pages are copied to the sparse file before the actual modification. That means the sparse file contains the old/point in time data (when the time the snapshot taken).
- Now if you query the snapshot all modified pages are read from sparse file and remaining all unchanged pages are read from the original (source database) data file.
Q. How to know the number of VLF created on a given database log file?
Ans:
Run DBCC LOGINFO; Number of rows returned = Total number of VLF. If it is more than 50 means we need to control the Auto-growth rate. Number of times Auto Grow happens means it increases the number of VLF’s.
Q. Any idea about boot page?
Ans:
In every database there is a page available which stores about the most critical information about that database. This page is called boot page. Boot Page is page 9 in first file on primary file group. We can examine the BOOTPAGE using DBCC PAGE or DBCC DBINFO
Q. Can we hot add CPU to sql server?
Ans:
Yes! Adding CPUs can occur physically by adding new hardware, logically by online hardware partitioning, or virtually through a virtualization layer. Starting with SQL Server 2008, SQL Server supports hot add CPU.
- Requires hardware that supports hot add CPU.
- Requires the 64-bit edition of Windows Server 2008 Datacenter or the Windows Server 2008 Enterprise Edition for Itanium-Based Systems operating system.
- Requires SQL Server Enterprise.
- SQL Server cannot be configured to use soft NUMA
Once the CPU is added just run RECONFIGURE then sql server recognizes the newly added CPU.
Q: How can we check whether the port number is connecting or not on a Server?
Ans:
TELNET <HOSTNAME> PORTNUMBER
TELNET PAXT3DEVSQL24 1433
TELNET PAXT3DEVSQL24 1434
Common Ports:
MSSQL Server: 1433
HTTP TCP 80
HTTPS TCP 443
Q: What is the port numbers used for SQL Server services?
Ans:
- The default SQL Server port is 1433 but only if it’s a default install. Named instances get a random port number.
- The browser service runs on port UDP 1434.
- Reporting services is a web service – so it’s port 80, or 443 if it’s SSL enabled.
- Analysis service is on 2382 but only if it’s a default install. Named instances get a random port number.
Q: Start SQL Server in different modes?
Ans:
Single User Mode (-m) : sqlcmd –m –d master –S PAXT3DEVSQL11 –c –U sa –P *******
DAC (-A): sqlcmd –A –d master –S PAXT3DEVSQL11 –c –U sa –P *******
Emergency: ALTER DATABASE test_db SET EMERGENCY
Q: How to recover a database that is in suspect stage?
Ans:
ALTER DATABASE test_db SET EMERGENCY
After you execute this statement SQL Server will shutdown the database and restart it without recovering it. This will allow you to view / query database objects, but the database will be in read-only mode. Any attempt to modify data will result in an error similar to the following:
Msg 3908, Level 16, State 1, Line 1 Could not run BEGIN TRANSACTION in database ‘test’ …..etc
ALTER DATABASE test SET SINGLE_USER
GO
DBCC CHECKDB (‘test’, REPAIR_ALLOW_DATA_LOSS) GO
If DBCC CHECKDB statement above succeeds the database is brought back online (but you’ll have to place it in multi-user mode before your users can connect to it). Before you turn the database over to your users you should run other statements to ensure its transactional consistency. If DBCC CHECKDB fails then there is no way to repair the database – you must restore it from a backup.
Q. Can we uninstall/rollback a service packs from SQL Server 2005?
Ans:
No not possible for SQL Server 2005. To rollback a SP you have to uninstall entire product and reinstall it.
For Sql Server 2008 you can uninstall a SP from Add/Remove programs.
Some people are saying that we can do it by backup and replace the resource db. But I am not sure about that.
Q. What is a deadlock and what is a live lock? How will you go about resolving deadlocks?
Ans:
Deadlock is a situation when two processes, each having a lock on one piece of data, attempt to acquire a lock on the other’s piece. Each process would wait indefinitely for the other to release the lock, unless one of the user processes is terminated. SQL Server detects deadlocks and terminates one user’s process.
A livelock is one, where a request for an exclusive lock is repeatedly denied because a series of overlapping shared locks keeps interfering. SQL Server detects the situation after four denials and refuses further shared locks. A livelock also occurs when read transactions monopolize a table or page, forcing a write transaction to wait indefinitely.
Q. SQL Server is not responding. What is action plan?
Ans:
Connect using DAC via CMD or SSMS
Connect via CMD
SQLCMD -A –U myadminlogin –P mypassword -SMyServer –dmaster
Once you connect to the master database run the diagnostic quires to find the problem
Correct the issue and restart the server
Find the errors from sql log using
SQLCMD –A –SmyServer –q”Exec xp_readerrorlog” –o”C:\logout.txt”
A long running query blocking all processes and not allowing new connections
Write a query and put the script file on hard disk Ex: D:\Scripts\BlockingQuery.sql
use master;
select p.spid, t.text
from sysprocesses p
CROSS APPLY sys.dm_exec_sql_text (sql_handle) t
where p.blocked = 0
and p.spid in
( select p1.blocked
from sysprocesses p1
where p1.blocked > 0
and p1.waittime > 50 )
From command prompt run the script on sql server and get the result to a text file
SQLCMD -A – SMyServer -i”C:\SQLScripts\GetBlockers.sql” -o”C:\SQLScripts\blockers.txt”
Recently added some data files to temp db and after that SQL Server is not responding
This can occur when you specify new files in a directory to which the SQL Server service account does not have access.
Start the sql server in minimal configuration mode using the startup parameter “–f”. When we specify –f the sql server creates new tempdb files at default file locations and ignore the current tempdb data files configuration. Take care when using –f as it keep the server in single user mode.
Once the server is started change the tempdb configuration settings and restart the server in full mode by removing the flag -f
A database stays in a SUSPECT or RECOVERY_PENDING State
Try to resolve this using CheckDB and any other DBCC commands if you can.
Last and final option is put the db in emergency mode and run CHECKDB with repair_allow_data_loss
(Note: Try to avoid this unless you don’t have any option as you may lose large amounts of data)
Q. What is your experience with third party applications and why would you use them?
Ans:
I have used some of the 3rd Party tools:
- SQL CHECK – Idera – Monitoring server activities and memory levels
- SQL DOC 2 – RedGate – Documenting the databases
- SQL Backup 5 – RedGate – Automating the Backup Process
- SQL Prompt – RedGate – Provides IntelliSense for SQL SERVER 2005/2000,
- Lite Speed 5.0 – Quest Soft – Backup and Restore
Benefits using Third Party Tools:
- Faster backups and restores
- Flexible backup and recovery options
- Secure backups with encryption
- Enterprise view of your backup and recovery environment
- Easily identify optimal backup settings
- Visibility into the transaction log and transaction log backups
- Timeline view of backup history and schedules
- Recover individual database objects
- Encapsulate a complete database restore into a single file to speed up restore time
- When we need to improve upon the functionality that SQL Server offers natively
- Save time, better information or notification
Q. Why sql server is better than other databases?
Ans:
I am not going to say one is better than other, but it depends on the requirements. We have number of products in market. But if I have the chance to choose one of them I will choose SQL SERVER because…..
- According to the 2005 Survey of Wintercorp, The largest SQL Server DW database is the 19.5 terabytes. It is a database of a European Bank
- High Security. It is offering high level of security.
- Speed and Concurrency, SQL Server 2005 system is able to handles 5,000 transactions per second and 100,000 queries a day and can scale up to 8 million new rows of data per day,
- Finally more technical peoples are available for SQL SERVER when we compare to any other database.
So that we can say SQL SERVER is more than enough for any type of application.
Q. Differences between SQL SERVER 2000 AND 2005?
Ans:
Security
- 2000: Owner = Schema, hard to remove old users at times Schema is separate.
- 2005: Better granularity in easily controlling security. Logins can be authenticated by certificates.
Encryption
- 2000: No options built in, expensive third party options with proprietary skills required to implement properly.
- 2005: Encryption and key management build in.
High Availability
- 2000: Clustering or Log Shipping requires Enterprise Edition and Expensive hardware.
- 2005: Clustering, Database Mirroring or Log Shipping available in Standard Edition. Database Mirroring can use cheap hardware.
Scalability
- 2000: Limited to 2GB, 4CPUs in Standard Edition. Limited 64-bit support
- 2005: 4 CPU, no RAM limit in Standard Edition. More 64-bit options offer chances for consolidation.
Q. What are the Hotfixes and Patches?
Ans:
Hotfixs are software patches that were applied to live i.e. still running systems. A hotfix is a single, cumulative package that includes one or more files that are used to address a problem in a software product (i.e. a software bug).
In a Microsoft SQL SERVER context, hotfixes are small patches designed to address specific issues, most commonly to freshly-discovered security holes.
Ex: If a select query returning duplicate rows with aggregations the result may be wrong….
Q. Why Shrink file/ Shrink DB/ Auto Shrink is really bad?
Ans:
In the SHRINKFILE command, SQL Server isn’t especially careful about where it puts the pages being moved from the end of the file to open pages towards the beginning of the file.
- The data becomes fragmented, potentially up to 100% fragmentation, this is a performance killer for your database;
- The operation is slow – all pointers to / from the page / rows being moved have to be fixed up, and the SHRINKFILE operation is single-threaded, so it can be really slow (the single-threaded nature of SHRINKFILE is not going to change any time soon)
Recommendations:
- Shrink the file by using Truncate Only: First it removes the inactive part of the log and then perform shrink operation
- Rebuild / Reorganize the indexes once the shrink is done so the Fragmentation level is decreased
Q. Which key provides the strongest encryption?
Ans:
AES (256 bit)
The longer the key, the better the encryption, so choose longer keys for more encryption. However there is a larger performance penalty for longer keys. DES is a relatively old and weaker algorithm than AES.
AES: Advanced Encryption Standard
DES: Data Encryption Standard
Q. What is the difference between memory and disk storage?
Ans:
Memory and disk storage both refer to internal storage space in a computer. The term “memory” usually means RAM (Random Access Memory). The terms “disk space” and “storage” usually refer to hard drive storage.
Q. What port do you need to open on your server firewall to enable named pipes connections?
Ans:
Port 445. Named pipes communicate across TCP port 445.
Q. What are the different log files and how to access it?
Ans:
- SQL Server Error Log: The Error Log, the most important log file, is used to troubleshoot system problems. SQL Server retains backups of the previous six logs, naming each archived log file sequentially. The current error log file is named ERRORLOG. To view the error log, which is located in the %Program-Files%\Microsoft SQL Server\MSSQL.1\MSSQL\LOG\ERRORLOG directory, open SSMS, expand a server node, expand Management, and click SQL Server Logs
- SQL Server Agent Log: SQL Server’s job scheduling subsystem, SQL Server Agent, maintains a set of log files with warning and error messages about the jobs it has run, written to the %ProgramFiles%\Microsoft SQL Server\MSSQL.1\MSSQL\LOG directory. SQL Server will maintain up to nine SQL Server Agent error log files. The current log file is named SQLAGENT.OUT, whereas archived files are numbered sequentially. You can view SQL Server Agent logs by using SQL Server Management Studio (SSMS). Expand a server node, expand Management, click SQL Server Logs, and select the check box for SQL Server Agent.
- Windows Event Log: An important source of information for troubleshooting SQL Server errors, the Windows Event log contains three useful logs. The application log records events in SQL Server and SQL Server Agent and can be used by SQL Server Integration Services (SSIS) packages. The security log records authentication information, and the system log records service startup and shutdown information. To view the Windows Event log, go to Administrative Tools, Event Viewer.
- SQL Server Setup Log: You might already be familiar with the SQL Server Setup log, which is located at %ProgramFiles%\Microsoft SQL Server\90\Setup Bootstrap\LOG\Summary.txt. If the summary.txt log file shows a component failure, you can investigate the root cause by looking at the component’s log, which you’ll find in the %Program-Files%\Microsoft SQL Server\90\Setup Bootstrap\LOG\Files directory.
- SQL Server Profiler Log: SQL Server Profiler, the primary application-tracing tool in SQL Server, captures the system’s current database activity and writes it to a file for later analysis. You can find the Profiler logs in the log .trc file in the %ProgramFiles%\Microsoft SQL Server\MSSQL.1\MSSQL\LOG directory.
Q. Explain XP_READERRORLOG or SP_READERRORLOG
Ans:
Xp_readerrorlog or sp_readerrorlog has 7 parameters.
Xp_readerrorlog <Log_FileNo>,<Log_Type>,<Keyword-1>,<Keyword-2>,<Date1>,<Date2>,<’Asc’/’Desc’>
Log_FileNo: -1: All logs
0: Current log file
1: No1 archived log file etc
Log_Type: 1: SQL Server
2: SQL Agent
KeyWord-1: Search for the keyword
KeyWord-2: Search for combination of Keyword 1 and Keyword 2
Date1 and Date2: Retrieves data between these two dates
‘Asc’/’Desc’: Order the data
Examples:
EXEC Xp_readerrorlog 0 – Current SQL Server log
EXEC Xp_readerrorlog 0, 1 – Current SQL Server log
EXEC Xp_readerrorlog 0, 2 – Current SQL Agent log
EXEC Xp_readerrorlog -1 – Entire log file
EXEC Xp_readerrorlog 0, 1, ’dbcc’ – Current SQL server log with dbcc in the string
EXEC Xp_readerrorlog 1, 1, ’dbcc’, ’error’ – Archived 1 SQL server log with dbcc and error in the string
EXEC xp_readerrorlog -1, 1, ‘dbcc’, ‘error’, ‘2012-02-21’, ‘2012-02-22′,’desc’
Search entire sql server log file for string ‘dbcc’ and ‘Error’ within the given dates and retrieves in descending order.
Note: Also, to increase the number of log files, add a new registry key “NumErrorLogs” (REG_DWORD) under below location.
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\MSSQL.X\MSSQLServer\
By default, this key is absent. Modify the value to the number of logs that you want to maintain.
Q. Can we track no of transactions / inserts / updates / deletes a Day (Without using profiler)? If yes how?
Ans:
You could use capture data change or change tracking:
http://msdn.microsoft.com/en-us/library/cc280519.aspx
Q. We have 300 SSIS packages those needs to be deployed to production, how can we make it easier / short way to deploy all SSIS packages at once.
Ans:
I would store these as XML based files and not in the MSDB database. With the configuration files, you can point the packages from prod to dev (and vice versa) in just a few seconds. The packages and config files are just stored in a directory of your choice. Resources permitting, create a standalone SSIS server away from the primary SQL Server
Q. We have a table which is 1.2 GB in size, we need to write a SP which should work with a particular point of time data (like snapshot) (We should not use snapshot Isolation as it take other 1.2 TB size)
Ans:
You may want to add insert timestamps and update timestamps for each record. Every time a new record is inserted, stamp it with the datetime, and also stamp it with the date time when updated. Also possibly use partitioning to reduce index rebuilds.
Q. What is RAID levels? Which one we have to choose for SQL Server user databases?
Ans:
Check out the charts in this document. It shows how the disks are setup. It will depend on what the customer wants to spend and level of reliability needed. Raid 5 is common, but see the topic ‘RAID 10 versus RAID 5 in Relational Databases’, in the document below. It’s a good discussion. Raid 10 (pronounced Raid one-zero) is supposed to have the best in terms of performance and reliability, but the cost is higher.
http://en.wikipedia.org/wiki/RAID
Q. How many datafiles I can put in Tempdb? What is the effect of adding multiple data files.
Ans:
By far, the most effective configuration is to set tempdb on its own separate fast drive away from the user databases. I would set the number of files based on # of cpu’s divided by 2. So, if you have 8 cpu’s, then set 4 tempdb files. Set the tempdb large enough with 10% data growth. I would start at a general size of 10 GB for each size. I also would not create more than 4 files for each mdf/ldf even if there were more than 8 cpu’s. you can always add more later.
http://msdn.microsoft.com/en-us/library/ms175527.aspx
http://msdn.microsoft.com/en-us/library/ms190768.aspx
Q. Let’s say a user is performing a transaction on a clustered server and failover has occurred. What will happen to the Transaction?
Ans:
If it is active/passive, there is a good chance the transaction died, but active/passive is considered by some the better as it is not as difficult to administer. I believe that is what we have on active. Still, active/active may be best depending on what the requirements are for the system.
Q. How you do which node is active and which is passive. What are the criteria for deciding the active node?
Ans:
Open Cluster Administrator, check the SQL Server group where you can see current owner. So current owner is the active node and other nodes are passive.
Q. What is the common trace flags used with SQL Server?
Ans:
Deadlock Information: 1204, 1205, 1222
Network Database files: 1807
Log Record for Connections: 4013
Skip Startup Stored Procedures: 4022
Disable Locking Hints: 8755
Forces uniform extent allocations instead of mixed page allocations 1118 – (SQL 2005 and 2008) To reduces TempDB contention.
Q. What is a Trace flag? Types of Trace Flags? How to enable/disable it? How to monitor a trace flag?
Ans:
http://blogs.technet.com/b/lobapps/archive/2012/08/28/how-do-i-work-with-trace-flags.aspx
Q. What are the limitations for RAM and CPU for SQL SERVER 2008 R2?
Ans:
| Feature | Standard | Enterprise | Datacenter |
| Max Memory | 64 GB | 2TB | Max Memory supported by windows version |
| Max CPU (Licensed per Socket, not core) | 4 Sockets | 8 Sockets | Max Memory supported by windows version |
Q. Do you know about Resource Database?
Ans:
All sys objects are physically stored in resource database and logically available on every database.
Resource database can faster the service packs or upgrades
Q. Really does resource faster the upgrades? Can you justify?
Ans:
Yes, in earlier versions upgrades requires dropping and recreating system objects now an upgrade requires a copy of the resource file.
We are also capable of rollback the process, because it just needs to overwrite the existing with the older version resource copy.
Q. I have my PROD sql server all system db’s are located on E drive and I need my resource db on H drive how can you move it?
Ans:
No only resource db cannot be moved, Resource db location is always depends on Master database location, if u want to move resource db you should also move master db.
Q. Can we take the backup for Resource DB?
Ans:
No way. The only way if you want to get a backup is use windows backup for option resource mdf and ldf files.
Q. Any idea what is the Resource db mdf and ldf file names?
Ans:
- mssqlsystemresource.mdf and
- mssqlsystemresource.ldf
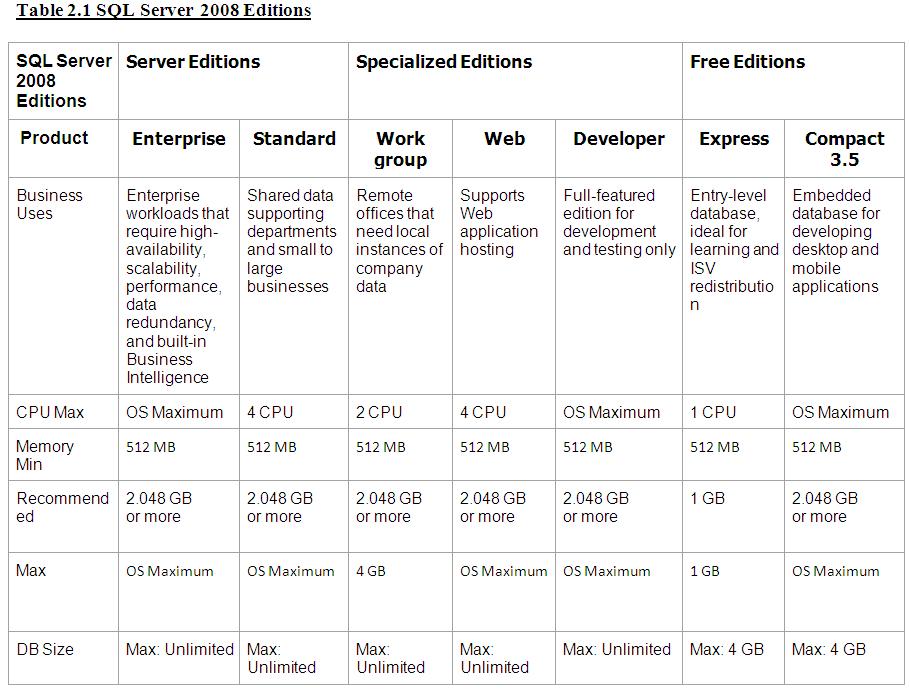
Q. Can you elaborate the requirements specifications for SQL Server 2008?
Ans:
Q. What you do if a column of data type int is out of scope?
Ans:
I do alter column to BigInt
Q. Are you sure the data type Bigint never been out of scope?
Ans:
Yes I am sure.
Let’s take few examples and see how many years will it take for BIGINT to reach its upper limit in a table:
(A) Considering only positive numbers, Max limit of BIGINT = 9,223,372,036,854,775,807
(B) Number of Seconds in a year = 31,536,000
Assume there are 50,000 records inserted per second into the table. Then the number of years it would take to reach the BIGINT max limit is:
9,223,372,036,854,775,807 / 31,536,000 / 50,000 = 5,849,424 years
Similarly,
If we inserted 1 lakh records per second into the table then it would take 2,924,712 yrs
If we inserted 1 million (1000000) records per second into the table then it would take 292,471 yrs
If we inserted 10 million (10000000) records per second into the table then it would take 29,247 yrs
If we inserted 100 million records per second into the table then it would take 2,925 yrs
If we inserted 1000 million records per second into the table then it would take 292 yrs
By this we would have understood that it would take extremely lots of years to reach the max limit of BIGINT.
Thank You
Top 7 SQL basic interview questions for SQL Developers
1000 Plus Professional SQL Server Interview Questions and Answers