It’s been a year since we posted a blog. It’s been the busiest year of my life. However, we strongly believe that learning is a journey and it should be a continuing process. Coming to the point, recently I had to handle a customer problem with the overall application performance. Found some interesting problems and thought of sharing the same.
Clustered Index on UNIQUEIDENTIFIER column
Problem Statement:
Clustered Index on UNIQUEIDENTIFIER column takes you through high-level problems with the GUID. We have a crucial database environment where we were facing some performance issues. We identified a few issues fixed them. While analyzing the overall database architecture, we observed a few interesting facts which are highly impacting the database performance. One of the major observations is having a clustered index on UNIQUEIDENTIFIER column on Transactional tables where we are seeing a lot of writes on those tables. When we captured the statistics below are the observations:
1. Index Rebuild is happening on Sunday afternoon
2. Index fragmentation (Index on UNIQUEIDENTIFIER) is reaching 65% by Monday afternoon
3. We do not get any maintenance window during the week as the application is running in 24X7
4. We are using the same fragmented index during the week till Saturday
5. On that clustered index Bad Page Splits Per Second is high > 38% of Batch Requests Per Sec
6. These indexes are being highly used across the application for both WRITES and READS
An expert from the customer side asked us to brief our analysis and the generic information on why clustered index on UNIQUEIDENTIFIER is creating the problem and the possible solutions. Here is our analysis and the solution suggested.
Q. What are the benefits of UNIQUEIDENTIFIER?
Ans:
As we know that it generates a unique number across the global database platform. Thereof merging data between systems and integration is easier.
It works like a gem when you are dealing with the distributed database systems.
It works perfectly when your data flow requires a MERGE replication
It’s a standard in specific domains and we may need to follow that.
Q. What are the Side Effects?
Ans:
It’s a 16 Byte value which is 4 times wider than your normal integer, so we need more space, More IO.
When we create a Non-Clustered-Index on other columns it includes the clustered key too, there we need more space and more IO.
More Page Splits if we don’t insert the sequential GUID then more fragmentation and it slower the Index Scan for Range operations.
Q. Does Page Splits are bad?
Ans:
Well, it’s not bad, when a new Page is getting added to the right side of your last leaf node.
Yes, it’s bad when a Page Split is frequently happening at mid of Index.
On your production if “Page Splits Per Sec” > 20% of Batch Requests Per Sec then it’s showtime. It’s an alarm which indicates that we need to focus on the solution.
Q. Does having clustered index on UNIQUEIDENTIFIER column degrades the performance?
Ans:
Yes, if you are not handling it properly. It’s clear that inserting/updating random values into a clustered index causes the BAD /middle-level Page Splits. Page Split is the default behavior, it works well when a page Split is happening at the end of Index but when it is happening in middle then we can expect the physical fragmentation on the clustered index. When your clustered index is fragmented more than 60% then it can’t speed up both READ and WRITE operations. I don’t say that using UNIQUEIDENTIFIER is a bad practice but creating a clustered index on top of it especially when we are generating values using NEW () is a bad practice.
No, if you are inserting the sequential unique values.
Best Practice: Avoid creating a clustered index on UNIQUEIDENTIFIER columns at the design level.
Q. I understand that it’s not a best practice. But, I can’t change the design now. Can you suggest the best possible solutions to handle the Clustered Index on a UNIQUEIDENTIFIER column?
Ans:
1.If your system is doing frequent INSERTS/DELETES/UPDATES on clustered-Index:
Identify any other column/columns that suit for Primary KEY or Create a BIGINT with Identity
Remove Clustered Index from GUID column
Add a Clustered index to the identified column
Create a Non-Clustered Index on GUID column
2.In most of the cases, solution 1 doesn’t work as it’s a core level change in design. No problem here is solution 2:
See if we can use NEWSEQUENTIALID() instead of NEW().
It generates a GUID but it’s a sequential GUID so that we need not worry about the page splits and logical/physical fragmentation
But, it has a limitation that we cannot explicitly generate the KEY value and it can be done only through DEFAULT constraint.
3.Man, my project is critical, solution 2 also required changes at all procedure/query level. We can’t go for it. Do we have any other options? Yes, solution 3 and the temporary fix:
Make sure you are using a re-index / rebuild plan ready and program it to handle your clustered index in such a way that whenever the index reaching 60% fragmentation apply for a rebuild job.
Q. I am curious to see how index fragmentation levels get impact when we are using a clustered index on a UNIQUEIDENTIFIER column. Can you take me through a simple example?
Ans:
Sure, here is a practical session that answers your question. Divided the script into 3 parts:
Part 1: Create two similar tables with a clustered index on key column (AddressID) with a default fill factor of 0/100.
Part 2: Insert data into tables
On Address_GUID we are explicitly inserting Random GUID values using NEWID ()
On Address_GUID_SEQ we are implicitly inserting sequential GUID values using NEWSEQUENTIALID () via DEFAULT constraint.
Part 3: We’ve inserted 10000 rows in both the tables. Data is almost similar except the GUID. Now we’ll check the fragmentation on clustered indexes from both the tables.


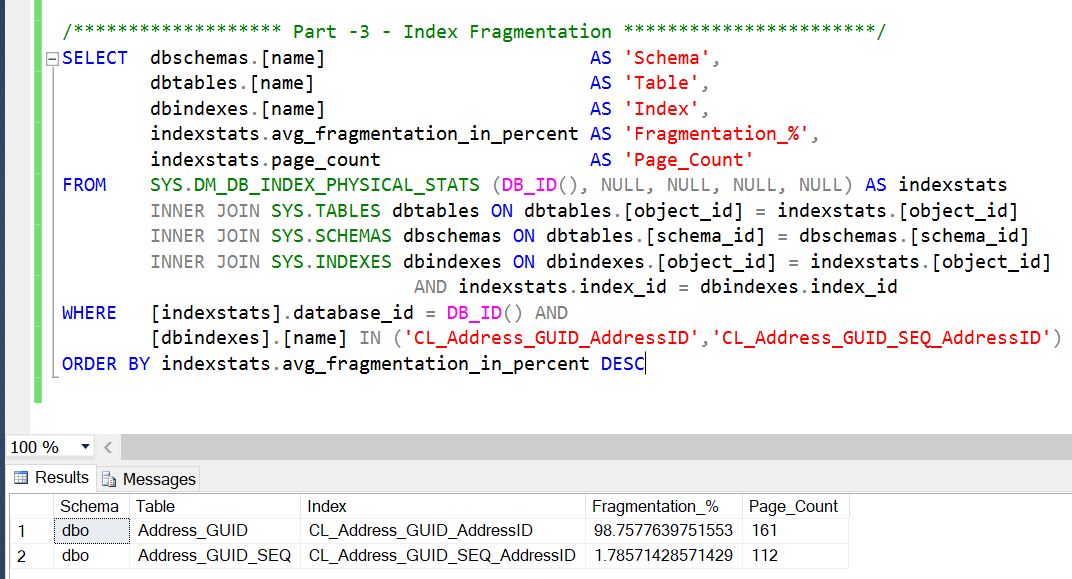












I think this is an informative post and knowledgeable. Thank you for sharing this wonderful post! I’m glad that I came across your article.
Really nice post. Thank you for sharing amazing information.
Python training in Chennai/Python training in OMR/Python training in Velachery/Python certification training in Chennai/Python training fees in Chennai/Python training with placement in Chennai/Python training in Chennai with Placement/Python course in Chennai/Python Certification course in Chennai/Python online training in Chennai/Python training in Chennai Quora/Best Python Training in Chennai/Best Python training in OMR/Best Python training in Velachery/Best Python course in Chennai