This post can help you to understand the “Covering Index Performance Impact in SQL Server”. First we’ll understand the covering index basics and we’ll see the performance impact using T-SQL code.
Q. What is a covering Index?
Ans:
A non-clustered index that is extended to include non-key columns in addition to the key columns is called as covering index.
Non-Key columns are not considered by the Database Engine when calculating the number of index key columns or index key size.
Need to use INCLUDE clause while creating index. This is mostly used to cover all columns in most frequently used queries in OLTP.
Covering index covers a query that means this index contains all columns which are used in SELECT, JOIN, WHERE clause
If you know that your application will be performing the same query over and over on the same table, consider creating a covering index on the table.
A covering index Without INCLUDE clause is same as composite index.
Q. Why covering index is required?
Ans:
Covering Index is used to remove KEY or RID Lookups. When we design a query in OLTP where the query usage frequency is very high and every time the query is issuing KEY/RID lookups then we can get benefit by creating covering index.
A covering index, which is a form of a composite non clustered index, includes all of the columns referenced in SELECT, JOIN, and WHERE clauses of a query.
Since the index is covering all columns from the query, the index contains the data you are looking for and SQL Server doesn’t have to look up the actual data in the table which reduce the logical and/or physical I/O, and boosting performance.
Also when we need to bypass the index limitations in number or size we can use Covering Index
Q. Since covering index improves the performance, I’ll create covering index to cover all of my queries. Does it make sense?
Ans:
My answer is strictly No! If the covering index gets too big, this could actually increase I/O and degrade the performance. While choosing covering index as a solution for a performance improvement we should consider the below parameters:
How frequently the query is getting executed in your application?
What is the frequency and volume of INSERTS and UPDATES on the table?
The current query response time is acceptable as per your business standards?
Example: We have a query which is having key lookups and execution time is 2 sec. If the same query is getting executed avg 350 to 400 times for every 5 min then creating a covering index can greatly improve the performance.
Q. After analyzing we decided to create a covering index for a query. While creating the covering index on which basis we should determine adding a column in Index main part and in INCLUDE clause?
Ans:
Columns that used for searching should be on main part of the Index which means columns that appear in JOINS, WHERE, GROUP BY and ORDER BY should be on Index main part.
Columns which are returned but not used in any search should be in INCLUDE part which means columns that appear in SELECT and HAVING should be in INCLUDE part.
Q. Can you explain the structure of an index if I create a clustered covering index on 5 columns in which 3 columns are in INCLUDE clause?
Ans:
I am surprised how you create a clustered covering index. We can’t create a covering index as clustered.
Q. If I create a Non-Clustered covering index with Col1 in Main clause and Col2, Col3, Col4 are in INCLUDE clause. Can you explain the B-Tree structure?
Ans:
B-Tree Non-Leaf Nodes: Values for Col1
B-Tree Leaf Nodes: Values for Col1, Col2, Col3 and Col4
Q. Can you take an example and show the Covering Index performance impact in SQL Server?
Ans:
We are using [AdventureWorks2014].
Create a New Table and Insert Data:
USE [AdventureWorks2014]
GO
-- Create Table
SELECT SalesOrderDetailID,
SalesOrderID,
ProductID,
OrderQty,
UnitPrice,
LineTotal
INTO SalesTestDetails
FROM SALES.SalesOrderDetail
--INSERT Data
INSERT INTO SalesTestDetails (SalesOrderID, ProductID, OrderQty, UnitPrice, LineTotal)
SELECT SalesOrderID, ProductID, OrderQty, UnitPrice, LineTotal
FROM SALES.SalesOrderDetail
GO 10
--Create a clustered index on OrderID
CREATE CLUSTERED INDEX CL_IX_OrderID ON SalesTestDetails(SalesOrderID);
--Create a Non-Clustered index on ProductID
CREATE NONCLUSTERED INDEX NON_CL_IX_ProductID ON SalesTestDetails(ProductID);
We are going to test the below SELECT Query:
SET STATISTICS IO ON;
SET STATISTICS TIME ON;
SELECT ProductID,
OrderQty,
UnitPrice,
LineTotal
FROM SalesTestDetails
WHERE ProductID = 895;
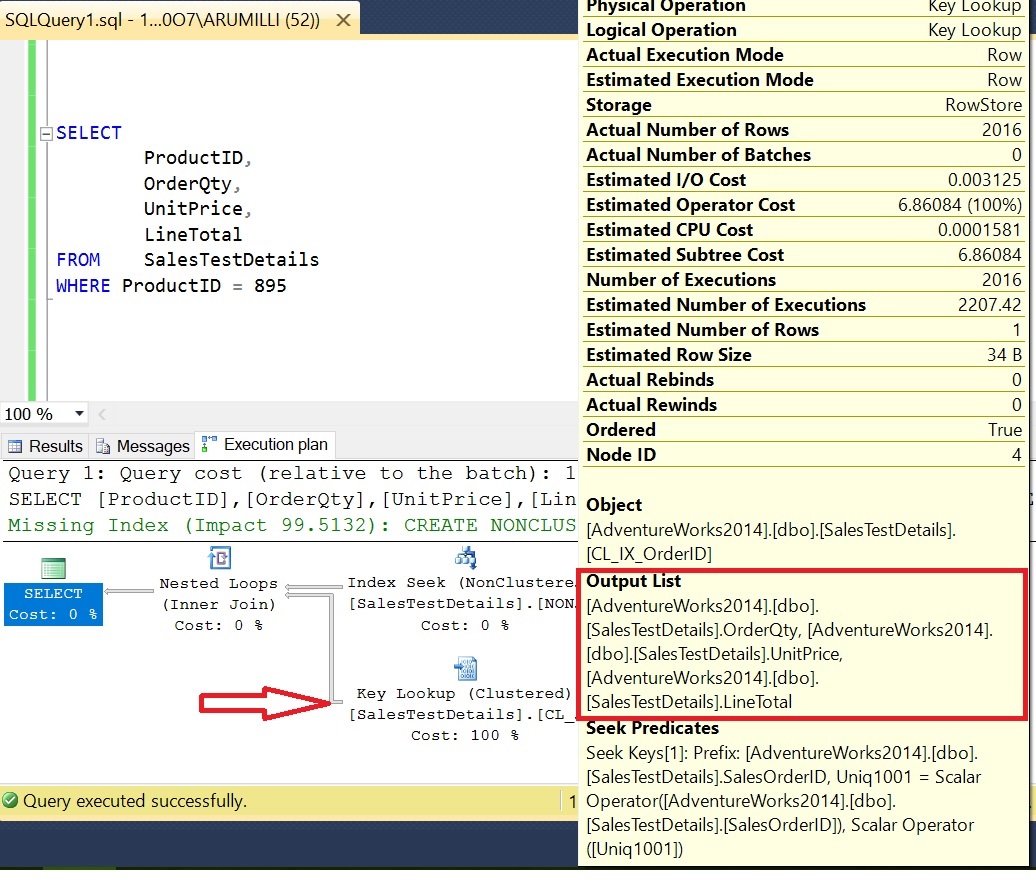
Execute With Out Covering Index:
Observations:
Since ProductID” Non-Clustered Index Seek is happening for the column “ProdutID”
Key Lookup happening for the columns “OrderQty”, “UnitPrice”, “LineTotal” that means for these columns its traversing the clustered index.
Logical Reads: 6194; CPU: 31 MS
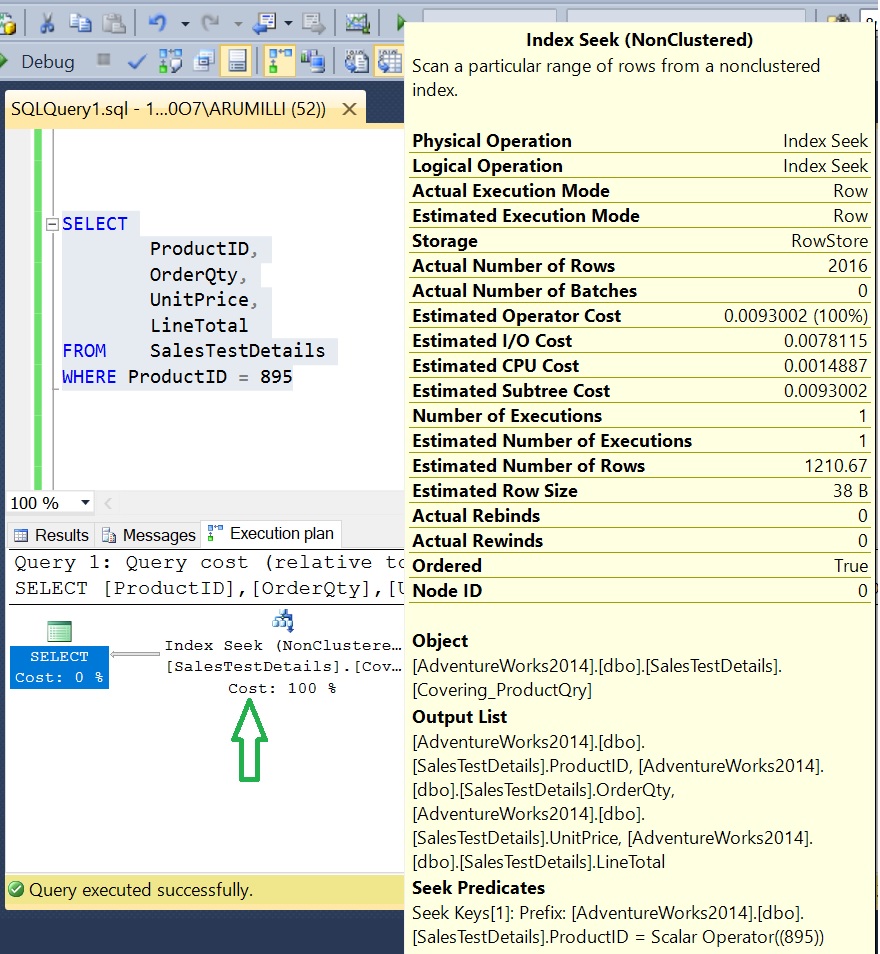
Execute With Covering Index:
Create Covering Index:
CREATE NONCLUSTERED INDEX Covering_ProductQry
ON SalesTestDetails (ProductID)
INCLUDE ( OrderQty, UnitPrice, LineTotal);
Observations:
Key Lookup is away from the execution plan.
Non Clustered Index Seek is happening for all columns
Logical Reads: 17; CPU: 0 MS
Summary:
Indexes are one of the critical and crucial parts that every SQL DBA and Developer should understand and use it in a proper way.
Covering index can avoid the key lookup for columns by covering the all required columns with a single index.
Covering Index is very helpful in improving the performance of frequently used queries.
We should be careful in choosing the KEY and NON-KEY columns while designing a covering index.
Consider the data modification and index maintenance operations while designing the covering index
This is an excellent article! It is very well written, informative without being too verbose. I will definitely reference it when troubleshooting poorly performing queries and quote it when explaining to my developer colleagues the how’s and why’s. BTW, I Love the Q and A format style of the article.















This is an excellent article! It is very well written, informative without being too verbose. I will definitely reference it when troubleshooting poorly performing queries and quote it when explaining to my developer colleagues the how’s and why’s. BTW, I Love the Q and A format style of the article.
Cedrick,
Thanks for your kind words. We are glad that you liked the article.
Thanks
Happy Reading
The One Team
Uday Arumilli